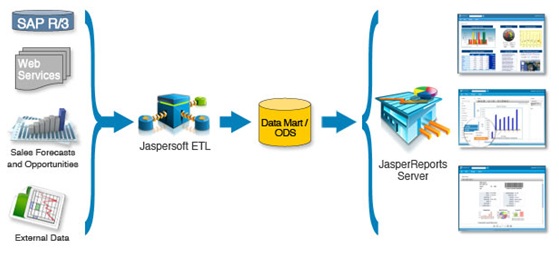
En 2012, on ne peut plus parler d’exploration des données sans parler de « Big Data », qui est le nouveau défi en Business Intelligence : la question est de savoir quoi faire de l’énorme flot de données récupérés via
- Les bases de données internes.
- Le suivi des consommateurs sur
-
- les sites : leurs achats, leurs comportements, leurs avis.
- les réseaux sociaux : leurs habitudes et les liens qu’entretiennent les consommateurs entre eux.
En effet de plus en plus d’informations sont récupérées et ce à tout instant.
On remarque que les entreprises ne savent pas gérer correctement cet énorme flot de données, qui ne peut plus être restitué dans des délais acceptable. Il s’agit donc pour les principaux acteurs de trouver des moyens de les traiter et de les restituer au mieux dans un temps minimal.
De nouvelles solutions assez similaire ont donc été proposées, les acteurs proposent des appliances (solutions packagées alliant la partie software et la partie hardware) .En pratique, l’appliance représente une solution plus performante, plus maintenable et propose une réelle sécurité en terme de stabilité des performances de la solution.
Aujourd’hui, elles reposent toute sur la même technologie, appelée la technologie « In-Memory ».
A) La technologie « In-Memory »
1) Aspects techniques
Cette technologie repose principalement sur le stockage des informations en mémoire vive, et prend en compte les avancées technologiques au niveau matériel et logiciel.
En effet, la baisse significative des coûts de la mémoire vive permet la mise en place d’un système de stockage approprié aux données des grandes sociétés. L’accès rapide à ces données étant un point essentiel, un système de mise en cache très performant a été mis en place, prenant en compte la localité spatiale et temporelle des données traitées. Afin de faire face à la croissance du volume de données, des avancées dans la puissance de traitement sont nécessaires. C’est pourquoi, le système In-memory exploite le parallélisme des systèmes multiprocesseurs et des processeurs multi-cœur.
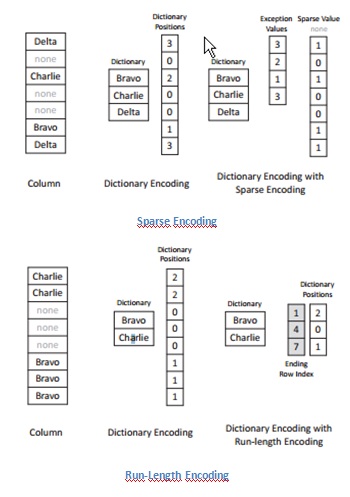
En plus des développements matériels, les avancées dans la technologie logicielle ont rendu le système « In-memory » possible. En effet, la mémoire vive a certes vu ses prix radicalement baissé, mais elle reste plus chère que le stockage en disque dur. Les techniques performantes de compression sont exigées pour gagner un bon compromis entre le coût de système et la performance. Ainsi, nous observons actuellement un facteur de compression de 5. Par exemple, avec 64Go de mémoire, le système peut stocker 320Go de données.
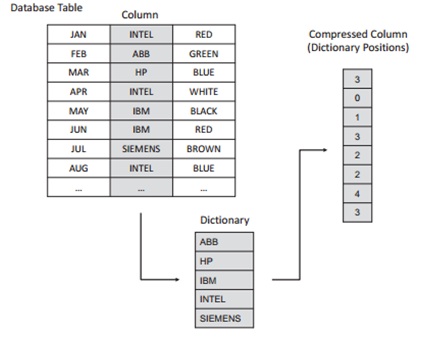
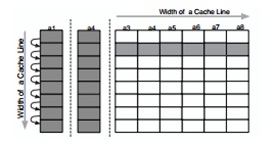
De plus, les bases de données peuvent-être gérées en colonne, selon les requêtes que l’on exécute.
Dans le cas d'une base de données orienté ligne, lors d'une requête, il est nécessaire de parcourir sur le disque toutes les colonnes des lignes traitées, afin de récupérer les champs correspondant aux colonnes nécessaire à la résolution de la requête.
Dans le cas d'un stockage en colonnes on travaille directement sur celles-ci, on va donc lire uniquement les colonnes qui sont nécessaires à la résolution de la requête. Comme toutes les lignes d'une colonne sont stockées de manière consécutive le temps de lecture de la colonne sera beaucoup plus rapide. Cela est particulièrement intéressant en BI car le nombre de colonnes lues pour répondre aux requêtes est faible (souvent moins de 5) et toujours bien inférieur au nombre de lignes.
Les colonnes peuvent aussi être triées. Ce qui réduit le nombre d'accès aléatoires dans le cas de recherches ce qui amène à une amélioration des performances. Mais il devient alors nécessaire de reconstruire entièrement la table en cas de modifications.
Exemple simplifié : Considérons cette base de données

Dans le cas d’une gestion en lignes, la base de données est stockée comme suit :
1,Smith,Joe,40000;
2,Jones,Mary,50000;
3,Johnson,Cathy,44000;
Nous avons donc bien un enregistrement par ligne.
Dans le cas d’une gestion en colonne, les enregistrements sont stockés de cette manière :
1,2,3;
Smith,Jones,Johnson;
Joe,Mary,Cathy;
40000,50000,44000;
Ce qui correspond à un enregistrement par colonne. Evidemment ceci n’est qu’une simplification et n’est pas représentatif de l’enregistrement au niveau physique, qui est considérablement modifié par l’indexation, le système de cache, etc.
Le stockage en colonne est donc meilleur que le stockage en ligne pour la recherche (donc particulièrement intéressant en décisionnel) et l'ajout, mais moins bon pour la modification (notamment le transactionnel).
Le système « In-memory » a été non seulement conçu afin de garantir un accès rapide aux données, mais aussi afin de répondre aux exigences spécifiques des entreprises.
Ainsi, ce système permet l’exécution de procédures stockées, les algorithmes travaillent près des données, et soulagent ainsi la couche réseau. Une autre exigence concerne le vieillissement des données. En effet les sociétés stockent en moyenne des données pour une période de dix ans, mais utilisent que 20% des données les plus récentes. Ce système sépare donc en 2 les données : une partie passive et une partie active. La partie passive est en lecture seul, et peut-être stockée dans un matériel de stockage plus lent, en mémoire flash par exemple. La partie active est celle conservée dans la mémoire vive et utilisée par l’application. Cette dernière peut spécifier le comportement à adopter pour le vieillissement des données, le système effectue ensuite le passage de la partie active à la partie passive de la donnée de manière transparente.
La mise à jour des données est effectuée à l’aide d’une base temporaire stockant toutes les insertions et mises à jour effectuées par l’application. Ces mises à jour sont stockées sous forme d’insertions, afin de prendre en compte l’évolution des données dans le temps et de pouvoir gérer les accès concurrents. De temps en temps cette base est fusionnée avec la base courante.
Enfin, le système utilise sa propre gestion des threads : il organise les threads en 2 pools : un pour les requêtes analytiques, l’autre pour les requêtes transactionnelles. Une gestion automatique est assurée selon les requêtes utilisateurs.
Le système « In-Memory » propose donc, à terme, un unique système permettant de traiter les requêtes transactionnelles et analytiques .
B) Les Gains liés à cette technologie
1) L’occasion de mettre en relation des données différentes
Un premier gain directement lié à la vitesse est la réduction des temps d’exécution : Un traitement durant plusieurs nuits peut être terminé en 1h voir moins.
Si la capacité technologique à traiter des téraoctets de données à la très grande vitesse est acquise, cela n’augmente pas pour autant la valeur « métier » que les organisations peuvent en tirer : celle-ci dépend de la qualité et de la pertinence des analyses qui utilisent ces données. Ainsi, lorsque toutes les données sont disponibles, il s’agit de trouver les bonnes relations (ex : mettre en évidence les coûts de transaction et les coûts logistiques d’une livraison d’un produit, pour comprendre la rentabilité de chaque ligne de commande) avant de prendre les bonnes décisions.
2) Un reporting décloisonné
Aujourd’hui, la difficulté est de maintenir l’articulation entre les vues agrégées et les rapports détaillés dont ont besoin les différents niveaux opérationnels. Par exemple, il est compliqué de fournir à la direction générale des indicateurs agrégés tout en maintenant l’accès à des centaines de millions de lignes pour les opérationnels. Le drill-down est limité par la structure même des rapports et des data-marts, d’où des difficultés de compréhension et de coordination entre les différentes couches et périmètres organisationnels.
En permettant de manipuler à la volée de très gros volumes de données, la BI In-Memory élimine la nécessité technique de multiplier les niveaux d’agrégation.
Cette technologie commence à être disponible chez certains éditeurs. Son coût d’ensemble reste élevé car, en plus d’un hardware adapté et de nouvelles licences il faut que les ERP et les outils décisionnels soient sur des versions récentes. Des prototypes, appelés « Proof of Concept », permettent de bien mesurer les enjeux et le retour sur de tels investissements.
3) L’analyse prédictive
Un deuxième apport majeur de la technologie In-Memory est de rendre l’analyse prédictive beaucoup plus accessible en permettant d’utiliser des données de multiples domaines et des données externes. L’objectif est de croiser différentes sources pour analyser le passé et finir par des projections, qui servent de base au développement de stratégies d’action.
Au minimum on peut comparer dans le détail des transactions passées par des clients similaires et en déduire un plan d’action direct pour augmenter la contribution de l’un ou de l’autre. Un acteur de la grande distribution pourra beaucoup plus facilement croiser ses gigantesques volumes de données transactionnelles (des centaines de millions de tickets de caisse par exemple) avec, des interactions « sociales » générées à partir de plates-formes mobiles, des données météorologiques, de géolocalisation pour développer des stratégies opérationnelles à court ou moyen terme, ou encore des données comportementales générées à partir des réseaux sociaux .
C) Les différentes solutions
A partir de cette technologie, les grands éditeurs proposent de nouvelles solutions
SAP
SAP, leader mondial a déjà mis sur le marché son application qui utilise cette technologie : HANA High Performance Analytics Appliance : une appliance matérielle et logicielle destinée à permettre aux applications compatibles de s’exécuter ‘In-Memory’.
Chez les clients, elle fonctionne pour l’instant aux côté des systèmes existants. Les clients de la plateforme HANA font états d’un gain de temps de 1 000, 10 000, voire plus exceptionnellement 100 000 .
Pour disposer de SAP HANA il faut pour l’entreprise, en plus de la couche matérielle, à minima des solutions SAP : l’ERP 6.0 avec EHP 4 ou 5, BW sur HANA .
SAP est toujours en quêtes d’opportunités liées au phénomène de Big Data, ainsi l’entreprise s’intéresse aux start-up, notamment en accueillant les plus innovantes et les plus intéressantes dans des forums qu’elle organise. Le but étant de réunir des entreprises pouvant être potentiellement rachetées. SAP a été intéressé par l’éditeur NextPrinciples , présent lors du 1er forum organisé par SAP propose un logiciel permettant de mettre en relation des données clients internes et celles en provenance des médias sociaux. Il s’agit ici de rajouter du contexte à l’information que l’on possède déjà.
Oracle
Oracle propose Exalytics , officialisé fin février qui repose sur une appliance composée d’un serveur Sun Fire, avec 1 To de RAM, 40 cœurs de processeurs Intel Xeon E7-4800, et une connectivité Infiniband 40 Gb/s et Ethernet 10 Gb/s. Côté applicatif, Exalytics embarque une version de la base de données TimesTen qui est la solution In-memory d’Oracle, avec une version mise à jour et optimisée de la suite analytique OBIEE (Business Intelligence Foundation Suite).
D’après Oracle, les tests comparatifs et les premiers retours des clients montrent que leur solution offre des gains de performance d'un facteur 10 à 100 pour le reporting OLAP relationnel (ROLAP) et les tableaux de bord, et d'un facteur pouvant atteindre 79 pour la modélisation OLAP multidimensionnelle (MOLAP).