 | Indexation de corpus spécialisés avec référentielsVeille technologique 2011-2012 |
Sommaire
I. Indexation et Recherche d’information
B. Systèmes de Recherche d'information
C. Différents modes d'indexation
2. Indexation libre ou indexation à l’aide d’un référentiel
D. Différents modes de recherche d’information
II. Méthodes d’indexation avec ou sans référentiels
A. Méthodes d'indexation sans référentiels
2. Exemple d'algorithme d'indexation : LSI (Latent Selantic Indexing)
B. Méthodes d'indexation avec référentiels
2. Exemple d’algorithme d’indexation : Kea++
C. Méthodes d'indexation étendues avec référentiels
2. Exemple d’algorithme d’indexation : Maui
A. Moteurs de recherche Internet
B. Solutions d’indexation et de recherche d’information
1. Indexation à partir de documents papiers
3. Les moteurs de recherche en entreprise
4. Des solutions d’indexation plus étoffées
Introduction
Le présent livre blanc a pour objectif de présenter les méthodes d'indexation de corpus spécialisés utilisant ou non des référentiels.
L’indexation vise à décrire un document à partir des notions et concepts présents dans son contenu afin de faciliter par la suite sa recherche.
Cette technique remonte à l'antiquité avec l'utilisation des notices documentaires*[1].
Avec le temps, il a semblé nécessaire d'organiser et de contrôler les mots-clés utilisés pour décrire les documents.
C'est ainsi qu’à la fin des années 1950, sont apparus les thésaurus*[2]. L'indexation peut dorénavant s'appuyer sur des référentiels*[3] pour pallier les problèmes d'imprécision et d'ambiguïté du langage naturel. Les mots-clés issus d'un vocabulaire contrôlé, en particulier quand ils sont normalisés par un thésaurus, sont dès lors appelés des descripteurs*.
Jusqu’alors les documents physiques et les notices documentaires ou descripteurs étaient gérés indépendamment. Mais avec l’apparition des documents numérisés, les descripteurs et le document se mettent à coexister sur un même support. Des métadonnées*[4] sont insérées dans le document lui-même, par exemple dans l’entête des documents HTML.
L'indexation a donc évolué au cours du temps avec l'apparition de nouvelles technologies et méthodes entrainant la mise en place de normes pour les encadrer et les homogénéiser.
Nous expliquerons donc dans une première partie en quoi consistent l’indexation et la recherche d'information. Puis nous aborderons une partie plus technique en considérant les méthodes d'indexation avec ou sans l'aide de référentiels. Enfin, dans une troisième partie, nous présenterons les solutions existantes.
Mots clés : indexation, référentiels, thésaurus, métadonnée, méthodes d'indexation, SKOS, MODS, système de recherche d’information.
Pour une meilleure compréhension de ce document, les termes suivis d’un astérisque sont définis en fin de rapport dans un glossaire.
I. Indexation et Recherche d’information
A. Définitions
1.

Figure 1: Schéma représentation d'un document (Source : http://www.slideshare.net/AntidotNet/perspectives-pour-les-rfrentiels-lheure-du-web-de-donnes?src=related_normal&rel=3562847)
Nous observons que le document est décrit à la fois par un concept et à la fois par des mots-clés.

Figure 2: Schéma de l'indexation
L'information est une richesse qu'il est important de détenir. Cependant, aujourd'hui, étant donné l'abondance d'information, le véritable enjeu réside dans le fait de parvenir à recueillir la bonne information au bon moment avec un coût minimum (en termes de temps et de personnes requises). Une information pertinente stockée quelque part est une information inutile si elle est impossible à retrouver. Le véritable enjeu est donc d'arriver à extraire l'information pertinente de la masse considérable d'information qui nous entoure.
Dans cette optique, l'indexation des documents est primordiale. En effet, l'indexation sert à optimiser le travail de recherche d'information. Une fois que les documents sont indexés, la recherche documentaire se réalise à partir de l'indexation en comparant par exemple les descripteurs d'un document avec la requête de recherche. Il n'est donc pas nécessaire de parcourir tout le document pour savoir si l'information recherchée s'y trouve. L'indexation est fortement liée à la recherche d'information.
b) Qui indexe ?
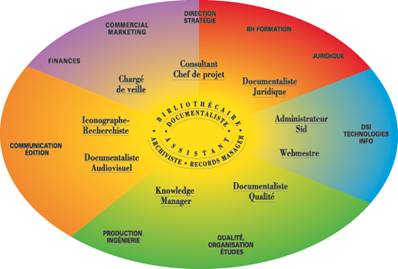
Figure 3: Schéma récapitulant les professionnels de l’information (source: http://www.adbs.fr/le-referentiel-des-metiers-et-fonctions-61928.htm?RH=MET_REFMETIER&RF=1204563910542)
c) Pour qui indexe-t-on ?
Il est possible de distinguer deux types de recherche d’information :
· La recherche d’information classique ou fermée qui consiste à rechercher un document dont l’existence ou la pertinence est acquise mais dont la localisation n’est pas connue.
· La recherche ouverte d’information qui consiste à réaliser une recherche sans savoir s’il existe un document susceptible de répondre au besoin.
Pour mieux comprendre, prenons l’exemple d’une personne désirant s’acheter un nouvel ordinateur. Si la personne sait déjà quel ordinateur acheter, on considère que c’est une recherche fermée. L’utilisateur désire juste localiser ou se renseigner sur cet ordinateur. Par contre si la personne ne sait pas du tout quel ordinateur acheter et donc s’il existe un ordinateur susceptible de répondre à ses attentes, on considère que c’est une recherche ouverte d’information.
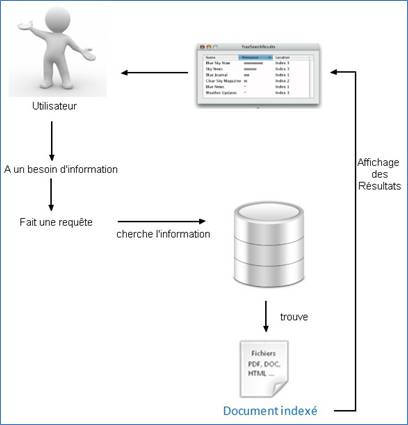
Figure 4: Schéma recherche d'information
Un utilisateur qui possède un besoin d’information réalise une recherche en soumettant une requête, généralement à un moteur de recherche. À partir de cette requête, un processus de recherche est mis en marche avec par exemple la consultation des bases de données recensant les documents indexés. La réponse à la requête est retournée sous la forme d’un lien vers le document recherché ou de l’affichage direct du document. L’utilisateur peut dès lors visualiser le résultat de sa recherche.
B. Systèmes de Recherche d'information
On constate donc que l'indexation et la recherche d'Information sont deux domaines très liés.
Les Systèmes de Recherche d'Information font la jonction entre ces deux domaines.
En effet, «un Système de Recherche d’Informations (SRI) est un système informatique qui permet de retourner à partir d’un ensemble de documents, ceux dont le contenu correspond le mieux à un besoin en informations d’un utilisateur, exprimé à l’aide d’une requête.»[9]
Un SRI inclut différentes fonctionnalités permettant de gérer, stocker, interroger, rechercher, sélectionner et représenter la grande masse d'information souhaitée.
Le schéma suivant résume la liaison entre indexation et recherche d'information ainsi que la place des référentiels dans ce contexte.
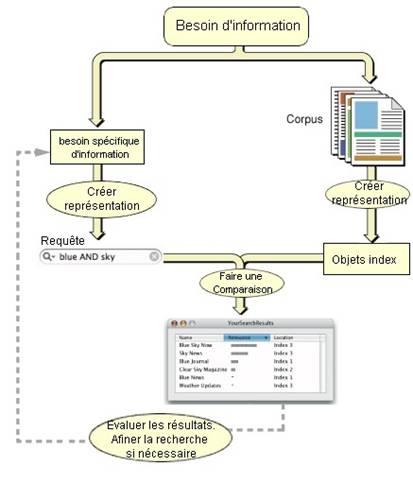
Figure 5: Schéma du système de Recherche d'Information (source : https://developer.apple.com/library/mac/#documentation/userexperience/Conceptual/SearchKitConcepts/searchKit_basics/searchKit_basics.html)
Ce schéma peut être lu de deux manières. Soit en partant de l'indexation avec le corpus indexé, soit en partant de la recherche avec le besoin spécifique d’information.
Un SRI se compose évidement d’un moteur de recherche qui permet de récolter l’information que l’on recherche. Mais si le moteur de recherche est un élément important d’un SRI, il y a d’autres composants sont impératifs. Un SRI peut notamment posséder un système de gestion des documents qui permet d’ajouter des documents. Il peut également avoir des modules d’importation et d’exportation qui permettent l’échange avec d’autres bases documentaires.
C. Différents modes d'indexation
1. Les types d'indexation
Traditionnellement l’indexation est réalisée par des documentalistes de manière manuelle. L’analyse du document est donc réalisée par une personne et non par une machine, ce qui est très coûteux en temps car l’indexeur doit lire et comprendre un document avant de pouvoir l’indexer correctement.
Avec l’augmentation de la quantité de documents à indexer, l’indexation tend à être automatisée.
L’indexation automatique consiste à extraire les mots les plus utilisés dans un texte, car on considère qu’un mot fréquemment utilisé est important. Ces termes sont alors qualifiés de mots-clés, ou de descripteurs lorsqu'ils sont issus d'un vocabulaire contrôlé.
Mais lors de l’indexation, on doit éviter de sélectionner un mot vide (le, de, un…) comme descripteur ou mot-clé. C’est la raison pour laquelle, lors d’une indexation automatique, on ignore généralement les mots courts, car ils sont considérés comme des mots vides par défaut. Cependant, cela peut entrainer une perte d’information. En effet cette méthode par exemple ignore le mot « os » alors que ce dernier est un mot important si on travaille dans le domaine de l’archéologie.
Un deuxième problème de l’indexation automatique se situe au niveau de la sémantique des mots, car le processus de l’indexation automatique compte le nombre d’occurrences d’un mot sans prendre en compte le sens de chaque mot. Par exemple, le mot « la » désigne à la fois un article ou une note de musique, de même le mot « orange » désigne une couleur et un fruit. Si les deux sens du mot sont utilisés dans un même texte le mot sera compté deux fois alors qu’il n’a pas le même sens.
Un autre problème rencontré par l’indexation automatique se situe au niveau des mots composés. Par exemple, considérons le mot composé « pomme de terre ». Ce dernier sera indexé au niveau de « pomme » et de « terre » mais pas au niveau de « pomme de terre » qui est son sens initial.
Pour améliorer l’indexation automatique, il est possible d’utiliser des dictionnaires de conjugaison. Ces dictionnaires ont pour but de retrouver l’infinitif de chaque verbe afin de trouver le nombre de fois qu’un verbe apparait sans tenir de sa conjugaison.
Cependant même si l’indexation automatique semble la plus appropriée lorsqu’un très grand nombre de documents doit être analysé, elle ne constitue pas la solution idéale dans le contexte de systèmes d’information nécessitant une précision élevé. En effet en raison des problèmes qui viennent d’être soulevés, les résultats obtenus sont bien moins pertinents que ceux résultant d’une indexation manuelle.
Une méthode d’indexation intermédiaire existe, c’est l’indexation semi-automatique ou indexation contrôlée. Dans un premier temps, un programme d’indexation automatique analyse les documents et propose des mots-clés, c’est-à-dire les mots qui sont les plus souvent répétés dans le texte, suivant le principe de l’indexation automatique. Ensuite dans un deuxième temps, une personne chargée de l’indexation relie les mots-clés proposés par le programme d’indexation et confirme ceux considérés comme pertinents. Cette méthode d’indexation permet de filtrer les résultats obtenus à partir de l’indexation automatique en supprimant des mots vides par exemple. Cette méthode semi-automatique a l’avantage d’améliorer la rapidité de l’indexation grâce à l’analyse automatique tout en conservant une précision élevée garantie par la validation humaine.
Le schéma ci-dessous résume les trois types d’indexation.

Figure 6: Schéma des différents types d’indexation
2. Indexation libre ou indexation à l’aide d’un référentiel
L'indexation peut être réalisée de manière libre ou à l'aide d'un référentiel.
Un référentiel rassemble sous un vocabulaire commun toutes les notions qui doivent être échangées, qui sont utilisées. C’est une mise en commun intellectuelle de terminologie, de pratiques ou de règles servant de référence.
Dans le cadre de l’indexation, les vocabulaires contrôlés forment des référentiels sur lesquels s'appuient les personnes pour indexer mais également les utilisateurs qui par la suite réalisent une recherche documentaire.
Un vocabulaire contrôlé est un ensemble de termes normalisés appelés descripteurs définis par un groupe, une communauté de pratiques.
Un vocabulaire contrôlé permet de pallier les problèmes de précision et d'ambiguïté du langage naturel. En effet, le langage que nous utilisons tous les jours, contient beaucoup de mots synonymes et polysémiques (mots possédant plusieurs sens).
Il peut alors apparaître le problème suivant: le vocabulaire utilisé par celui qui indexe est différent du vocabulaire utilisé par la personne qui réalise une recherche. Il en résulte des réponses qui ne correspondent pas au sujet recherché (appelé « bruit » du système) ou des résultats pertinents qui ne sont pas retournés à l’utilisateur (appelé « silence » du système). Or l'objectif est de diminuer à la fois le bruit et le silence pour améliorer la précision des réponses lors d'une recherche documentaire. Le vocabulaire contrôlé est donc une solution efficace pour y parvenir puisqu'il garantit qu'un sujet sera décrit toujours avec les mêmes descripteurs. Ainsi, si plusieurs termes désignent un même concept, un seul d'entre eux sera choisi. Les vocabulaires contrôlés permettent donc une homogénéité du mode d'indexation qui dépend alors moins de l'indexeur. Des personnes qui indexent le même document auront plus de chance de choisir les mêmes descripteurs. En outre, les personnes qui réalisent une recherche pourront utiliser le même vocabulaire contrôlé augmentant ainsi les chances d’utiliser les mêmes termes que ceux employés par les indexeurs.
Les vocabulaires contrôlés visent donc à harmoniser le vocabulaire des indexeurs et celui des utilisateurs (personnes réalisant une recherche), et à guider les indexeurs et les utilisateurs dans le choix des termes appropriés.
Les vocabulaires contrôlés recouvrent :
- les listes de synonymes qui permettent de réaliser la recherche également sur tous les termes équivalents.
- les listes d'autorités telles que la liste RAMEAU*[10]. D'après l'association des professionnels de l'information et de la documentation (ADBS), les listes d'autorité correspondent à la "liste des termes normalisés, soit des mots matières, soit des noms propres, qui doivent être obligatoirement et nécessairement utilisés dans l'indexation."
- les taxonomies pour lesquelles les termes du vocabulaire contrôlé sont organisés sous forme hiérarchique simple. Cette hiérarchisation correspond à une spécialisation ou à une généralisation. D'un vocabulaire contrôlé (ensemble de descripteurs), nous passons donc à un vocabulaire organisé (ensemble de relations entre les descripteurs). Les taxonomies mettent, par exemple, en exergue le fait que les mammifères correspondent à une sous-catégorie des vertébrés.
- les thésaurus qui, tout comme les taxonomies, correspondent à un vocabulaire contrôlé et organisé. Cependant, en plus de la hiérarchisation des descripteurs, les thésaurus donnent de l'information sur les termes similaires. Un thésaurus traduit donc des relations de spécialisation du type "sous-catégorie" et des relations d'association du type "relatif à" ou "similaire à".
Ainsi lorsque l’on recherche un mot avec un thésaurus, la recherche s’étendra à tous les mots équivalents, parents et associés. L’utilisateur aura donc plus de chance de trouver un résultat correspondant à sa recherche.
Par exemple un thésaurus reliant « vente » à « production », « voiture » à « véhicule », et « France » à « Europe », permettra pour une question portant sur les ventes de voitures en France de trouver des ressources indexées avec « production » « véhicule » « Europe ».
Le schéma ci-dessous résume les différents vocabulaires contrôlés.
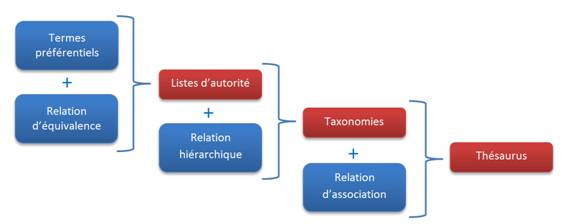
Figure 7: Schéma explicatif des différents vocabulaires contrôlés (inspiré de l’article « Controlled Vocabularies: A Glosso-Thesaurus » écrit par Fred Leise, Karl Fast et Mike Steckel en 2003)
De nombreuses normes ont été mises en place pour harmoniser l'utilisation des référentiels et pour assurer leur interopérabilité. Ces différentes normes sont publiées par des organismes de normalisation tels que l'ISO (Organisation Internationale de Normalisation) qui est un organisme international de normalisation. En France c’est l’AFNOR qui est chargée de la normalisation. Le NISO (National Information Standards Organization) est quant à lui un organisme de normalisation Américain.
Afin de se faire une idée de ces normes, voici une liste non-exhaustive :
En 1974 une norme internationale ISO 2788 a été mise en place pour les thésaurus monolingues.
Quatre ans plus tard, en 1978 une norme AFNOR Z47-102 a été instaurée pour définir les principes généraux pour l’indexation des documents.
Puis en 1981 la norme AFNOR Z47-100 a été homologuée pour les thésaurus monolingues.
La norme ANSI/NISO Z39.19 qui date de 2005 concerne les vocabulaires contrôlés.
La dernière norme relative aux thésaurus date de 2011. C’est la norme ISO 25964-1 qui concerne les thésaurus monolingues et multilingues.
À l'inverse de l'indexation utilisant un référentiel, l'indexation libre ne s'appuie pas sur un vocabulaire contrôlé. C'est le cas des folksonomies aussi appelées indexations collaboratives, potonomies ou peuplonomies.
Une folksonomie est un système d’indexation collaborative dont le vocabulaire n’est ni contrôlé ni organisé. Ce type d’indexation n’est pas réalisé par des documentalistes mais par des non-spécialistes, par tout un chacun. Les termes utilisés pour décrire les documents sont souvent appelés mots-clés, tags ou étiquettes. N’étant pas du tout prédéfinis, ces termes dépendront de l’indexeur. Un même document sera donc décrit avec des mots-clés différents d’un indexeur à l’autre. La recherche d’information sera donc réalisée en passant d’un mot-clé à un autre, d’un synonyme à un autre.
La folksonomie exploite le principe de sérendipité (fait de trouver tout autre chose que ce que l’on cherchait). En effet, en passant d'un tag à l'autre, et par l'utilisation de mots-clés détournés, l'utilisateur peut tomber sur de l'information qu'il ne cherchait pas à l'origine. La recherche peut paraître plus longue mais l’avantage c’est que l’abondance de tags pour un même document augmente les chances que les termes utilisés pour indexer un document correspondent à ceux utilisés par la personne qui réalise la recherche.
Cette forme d'indexation est peu coûteuse en argent puisqu'elle ne nécessite pas le recours à un professionnel, mais également en temps puisque qu'elle fait appel au temps de chaque utilisateur, ce qui permet d'indexer une grande quantité d'information.
La folksonomie est donc une forme d'indexation simple, peu couteuse et qui s'adapte rapidement aux évolutions de la langue, cependant elle présente quelques désavantages. En effet, les tags ne peuvent pas être organisés, hiérarchisés comme c'est le cas des thésaurus par exemple. De plus, la folksonomie est sensible à l'orthographe, à la casse, la conjugaison, les singuliers-pluriels. Il en résulte que des tags synonymes ou identiques ne seront pas compris comme tels entraînant une surabondance de tags.
En outre, deux utilisateurs peuvent partager un tag identique, mais en avoir une conception différente, que ce soit par exemple du fait de la culture, de la mentalité ou du niveau de connaissance. Il leur manque un référentiel commun pour indexer.
Le problème majeur de la folksonomie se révèle être le bruit et la pertinence des tags. En effet, les personnes qui indexent dans les folksonomies ne sont pas des professionnels, il existe donc un risque important d'erreur, volontaire (acte de malveillance) ou involontaire (connaissance erronée).
L'indexation, qu'elle soit libre ou contrôlée, présente des avantages et des inconvénients. L'utilisation de l'une ou de l'autre forme d'indexation dépendra entre autres de la quantité de documents à indexer, des moyens humains disponibles et de la qualité de l’indexation recherchée.
D. Différents modes de recherche d’information
Pour faire une recherche d'information, il est possible de passer par plusieurs types de moteurs de recherche. En effet, suivant le type d'information que l'utilisateur souhaite rechercher, pour avoir une information pertinente, il devra se tourner vers différents outils de recherche.
Le principal moteur Web de recherche utilisé aujourd'hui est Google pour des informations générales. Google Scholar est quant à lui, un outil pertinent pour réaliser des recherches sur les thèses ou documents scientifiques (ou littérature grise).
Mais le moteur de recherche utilisant des termes dits "sémantiques" n'est pas le seul type utilisé.
Il existe également des moteurs de recherche utilisant directement les thésaurus et affichant un résultat sous forme de graphe. Les sites thesaurus.com ou visual thesaurus en sont de bons exemples.
Il y a aussi les moteurs de recherche utilisant des mots couplés à des recherches sur les réseaux sociaux tels que Volunia.
Nous verrons plus en détail les solutions proposées pour la recherche d’information dans la troisième partie.
II. Méthodes d’indexation avec ou sans référentiels
Lorsque l’on souhaite indexer des documents au sein d’une institution, il est fréquent de mettre en place une politique d’indexation qui regroupe des recommandations et des directives précises quant à l’indexation à mettre en place. Dans ce cadre, des référentiels (exemple : langages documentaires) peuvent être utilisés lors de ce processus.
Dans cette partie, nous décrirons plusieurs méthodes d’indexation qui s’appuient ou non sur des référentiels pour traiter des documents.
A. Méthodes d'indexation sans référentiels
1. Principe
Une méthode d'indexation sans référentiels ne se base pas sur des thésaurus, ontologies ou d'autres référentiels. L'indexation se base uniquement sur le document. Le processus général se déroule selon les étapes suivantes: filtrage des mots clés, lemmatisation et/ou racinisation, modélisation vectorielle et enfin pondération. Ce processus est utilisé par les moteurs de recherche « classiques » (non-sémantiques) pour indexer des documents.
a) Filtrage des mots
L’approche classique pour indexer un document (texte) est de relever les mots qui apparaissent le plus fréquemment et de les utiliser comme index (ou termes). Néanmoins, il faut ignorer les mots vides tels que « le », « la », « de » etc. En effet, ils sont très présents dans le texte mais n’apportent pas de sens. Pour ce faire on utilise une liste de ces mots appelée anti-lexique (ou stop words) pour les filtrer.
b) Lemmatisation et Racinisation
D’autres problèmes sont également à résoudre lors d’une indexation automatique. Ce sont les mots conjugués ou accordés ainsi que les préfixes et les suffixes. Les solutions à ces problèmes sont la lemmatisation et la racinisation (ou stemming). Ces deux méthodes permettent de réduire le nombre de mots à indexer dans un texte.
Lemmatisation : La lemmatisation consiste à trouver un lemme en partant de ses flexions. Les flexions sont les différentes formes qu’un même mot peut prendre. Un lemme est la forme non conjuguée et non accordée d'un mot. Prenons comme exemple le verbe « manger ». Il n’est ni conjugué, ni accordé donc c’est un lemme. Ces flexions sont : « mangera », « mangeons », « avait mangé » etc. La lemmatisation en contexte (en s'aidant de la phrase contenant le mot à lemmatiser) ou hors contexte (sans tenir compte du contexte).
Voici une liste non exhaustive de logiciels et de ressources traitant de la lemmatisation :
· TreeTagger est un outil qui permet d'annoter un texte des informations de lemmatisation,
· WinBrill est un outil qui va, pour chaque mot d’un texte, déterminer sa catégorie grammaticale, son genre, son nombre (...),
· LEFFF est un lexique qui décrit pour chaque entrée lexicale son lemme,
· etc.
Certains lemmatiseurs peuvent traiter plusieurs langues (exemple : TreeTagger traite les langues anglaise et allemande).
Racinisation (ou stemming) : La racinisation consiste à transformer un mot (une flexion) en sa racine (ou radical). Un racinisateur (ou stemmer) cherche la racine d’un mot en fonction de sa forme et de la langue souhaitée. Par exemple, le mot « majestueux » sera transformé par un racinisateur en sa racine « majestu ». On voit dans cet exemple que la racine n'est pas forcément un mot réel.
Les trois algorithmes majeurs de racinisation sont :
· L’algorithme de Lovins (1968) : http://www.comp.lancs.ac.uk/computing/research/stemming/Links/lovins.htm
· L’algorithme de Paice/Husk (1980) : http://www.comp.lancs.ac.uk/computing/research/stemming/Links/paice.htm
· L’algorithme de Porter (1980) : http://tartarus.org/martin/PorterStemmer/
Il existe bon nombre d’outils de racinisation. L’un d’entre eux est Snowball, qui a été inventé par Martin Porter (le créateur de l’algorithme de Porter). Il existe des racinisateurs Snowball pour diverses langues (français, anglais, espagnol etc.) disponibles sur http://snowball.tartarus.org/.
c) Modélisation vectorielle
Après être passé par toutes ces étapes le document est représenté sous la forme d’un vecteur. La dimension de ce vecteur est égale au nombre total d’index. Chaque composante du vecteur représente la fréquence de l’index (nombre d’occurrences de l’index en réalité) correspondant dans le document. En appliquant cette opération sur l’ensemble des documents on obtient une matrice dont les colonnes représentent les documents.
Prenons un exemple de trois documents très courts :
· Doc1 : Ceux qui achètent des couches achètent du lait. Ceux qui achètent du lait aiment les pommes.
· Doc2 : Ceux qui achètent des couches achètent aussi du pain.
· Doc3 : Ceux qui achètent des pommes n’achètent pas de bière.
En considérant que les index possibles soient : « couche », « bière », « lait », « pain » et « pomme » voici la matrice du corpus de documents :
|
Termes |
Doc1 |
Doc2 |
Doc3 |
|
Couche |
1 |
1 |
0 |
|
Bière |
0 |
0 |
1 |
|
Lait |
2 |
0 |
0 |
|
Pain |
0 |
1 |
0 |
|
Pomme |
1 |
0 |
1 |
Figure 8 Exemple de matrice de corpus de document
d) Pondération tf-idf
Généralement on utilise des
pondérations au lieu des fréquences pour tenir compte de la rareté d’un index
dans le corpus. Ce poids tient compte de la fréquence (nombre d’occurrences)
de l’index dans le document mais aussi de sa fréquence dans l’ensemble de tous
les documents. Voici pourquoi on utilise ce poids de rareté. Si un utilisateur
fait une recherche sur un terme T, plus un document a une fréquence élevée sur ce
terme, plus il a de chance de répondre à la requête de l’utilisateur.
Cependant, si T est présent dans de nombreux documents il ne discriminera pas
beaucoup la recherche. En tenant compte de la rareté d’un terme on aidera
l’utilisateur à trouver des documents qui répondront de manière pertinente à
sa requête. On note ![]() (term frequency) la fréquence
d’un terme dans un document. La matrice précédente contient des valeurs de
(term frequency) la fréquence
d’un terme dans un document. La matrice précédente contient des valeurs de ![]() .
On note
.
On note ![]() (inverse document frequency) la
rareté d’un terme :
(inverse document frequency) la
rareté d’un terme :
![]()
![]() est l’
est l’![]() du
terme
du
terme ![]()
![]() est le nombre total de documents
dans le corpus
est le nombre total de documents
dans le corpus
![]() est le nombre de documents où le
terme
est le nombre de documents où le
terme ![]() apparaît
apparaît
Voici les ![]() de nos termes :
de nos termes :
|
Termes |
|
|
Couche |
0,6 |
|
Bière |
1,6 |
|
Lait |
1,6 |
|
Pain |
1,6 |
|
Pomme |
0,6 |
Figure 9 Les idf de nos termes
On peut noter que plus un terme
est rare, plus son ![]() est grand.
est grand.
Enfin, il suffit maintenant de
multiplier les ![]() de la première matrice par l’
de la première matrice par l’![]() de
chaque terme pour retrouver une nouvelle matrice tenant compte de la
pondération :
de
chaque terme pour retrouver une nouvelle matrice tenant compte de la
pondération :
|
Termes |
Doc1 |
Doc2 |
Doc3 |
|
Couche |
0,6 |
0,6 |
0 |
|
Bière |
0 |
0 |
1,6 |
|
Lait |
3,2 |
0 |
0 |
|
Pain |
0 |
1,6 |
0 |
|
Pomme |
0,6 |
0 |
0,6 |
Figure 10 La nouvelle matrice du corpus
Cette nouvelle matrice contient des valeurs de pondération ![]() .
.
Bien que le processus décrit précédemment ne donne pas toutes les spécificités des nombreux algorithmes d'indexation, il donne un schéma global reprit par la plupart d'entre eux. Il sert aussi de base pour les algorithmes utilisant des référentiels (voir ci-après).
2. Exemple d'algorithme d'indexation : LSI (Latent Selantic Indexing)
L’indexation sémantique consiste à lier les mots d’un document à un concept (le sens du mot). Prenons l’exemple du mot « puma ». Lors de l’indexation l’algorithme doit déterminer si le mot « puma » fait référence à l’animal ou à la marque.
Le LSI utilise une méthode statistique (la décomposition en valeurs singulières) pour regrouper les mots ayant un même « sens ». Par exemple, le LSI regroupera les mots « portable » et « laptop » car ils apparaissent souvent dans le même contexte.
Voici le processus d’indexation du LSI :
1. Matrice d’occurrence – Le LSI calcule dans un premier temps un matrice d’occurrence de type tfxidf obtenu selon le processus décrit précédemment. Voici la matrice d’occurrence de l’exemple précédent :
|
Termes |
Doc1 |
Doc2 |
Doc3 |
|
Couche |
0,6 |
0,6 |
0 |
|
Bière |
0 |
0 |
1,6 |
|
Lait |
3,2 |
0 |
0 |
|
Pain |
0 |
1,6 |
0 |
|
Pomme |
0,6 |
0 |
0,6 |
Figure 11 Matrice d'occurrence M
2. Décomposition en valeurs singulières – La matrice d’occurrence est décomposée en produit de trois matrices :
![Description : \begin{eqnarray*}\left [
\begin{array}{ccc}
-0.19 & 0.25 & 0.23 \\
-0.02 & -0.66 & 0.66 \\
-0.96 & 0.0 & -0.12 \\
-0.02 & 0.66 & 0.66 \\
-0.19 & -0.25 & 0.23
\end{array}
\right ]
\left [
\begin{array}{ccc}
3.32 & 0 & 0 \\
0 & 1.71 & 0 \\
0 & 0 & 1.70
\end{array}
\right ]
\left [
\begin{array}{ccc}
-1 & -0.045 & -0.045 \\
0 & 0.7071 & -0.7071 \\
-0.06 & 0.7057 & 0.7057
\end{array}
\right ]
=\\
\left [
\begin{array}{ccc}
0.6 & 0.6 &0 \\
0 &0& 1.6\\
3.2 & 0 & 0\\
0 & 1.6 & 0\\
0.6 & 0 & 0.6
\end{array}
\right ]
\end{eqnarray*}](LivreBlanc_fichiers/matrice.jpg)
Figure 12 Décomposition en valeurs singulière (benhur.teluq.uqam.ca)
La première colonne de U se comprend comme suit : « -0.19 pour couches, -0.02 pour bière, -0.96 pour lait, -0.02 pour pains, -0.19 pour pomme ». La matrice V permet de regrouper les 5 termes en 3 groupes pondérés. La diagonale de V donne la valeur de ces pondérations.
3. Matrice réduite - Cette étape consiste à réduire la matrice V pour ne garder que les pondérations les plus fortes. Dans notre cas nous avons supprimé la dernière pondération pour ne garder que 2 groupes. Cette suppression entraîne une perte d’information mais permet de se focaliser sur les termes les plus influents. L’enjeu est donc de choisir le nombre de groupe à conserver.
On peut ensuite calculer une matrice réduite M’ à partir de la décomposition en valeurs singulières.
![Description : \begin{eqnarray*}\left [
\begin{array}{ccc}
-0.19 & 0.25 & 0.23 \\
-0.02 & -0.66 & 0.66 \\
-0.96 & 0.0 & -0.12 \\
-0.02 & 0.66 & 0.66 \\
-0.19 & -0.25 & 0.23
\end{array}
\right ]
\left [
\begin{array}{ccc}
3.32 & 0 & 0 \\
0 & 1.71 & 0 \\
0 & 0 & 0
\end{array}
\right ]
\left [
\begin{array}{ccc}
-1 & -0.045 & -0.045 \\
0 & 0.7071 & -0.7071 \\
-0.06 & 0.7057 & 0.7057
\end{array}
\right ] \approx\\
\left [
\begin{array}{ccc}
0.62 & 0.33 &-0.27 \\
0.071 &-0.80 & 0.80\\
3.19 & 0.14 & 0.14\\
0.071 & 0.80 & -0.80\\
0.62 & -0.27 & 0.32
\end{array}
\right ]
\end{eqnarray*}](LivreBlanc_fichiers/matrice2.jpg)
Figure 13 Calcul de la matrice réduite M'
Cette matrice réduite est une approximation de la matrice d’occurrence. Elle permet de « débruiter » la matrice d’occurrence, c’est-à-dire de la nettoyer des termes qui n’apparaissent que très rarement. Dans notre exemple on regroupe ainsi les cinq termes en deux groupes.
Grâce au LSI on résout les problèmes de synonymie et de polysémie.
Il existe des algorithmes du même genre : PLSI (Indexation Sémantique Latente Probalistique), LDA (Latest Dirichlet Allocation), HAL (Hyperspace Analogue To Language)*.
B. Méthodes d'indexation avec référentiels
Principe
- Les descripteurs, qui sont utilisés pour indexer un document. Ceux-ci constituent l'ensemble des mots autorisés pour indexer.
- Les non-descripteurs qui ne peuvent pas être employés pour indexer un document, mais qui, parce qu’ils représentent des notions susceptibles de faire l’objet régulier d’interrogations (lors d’une recherche), renvoient au descripteur à utiliser.
Le thésaurus retient une seule forme pour un concept. Par exemple, dans le thésaurus en éducation pour la santé, «oncologie » est un non-descripteur qui renvoie au descripteur « cancérologie ». Dans ce cas, si un document relatif au domaine de la santé est indexé, le mot « oncologie » ne sera pas défini comme un mot-clé même s’il apparaît dans le document. Cependant, par le lien existant entre les termes « oncologie » et « cancérologie », si le mot « oncologie » représente une notion pertinente du document, ce dernier connaîtra comme mot-clé le terme « cancérologie ».
Aussi, la prise en compte des relations entre les termes permet de rendre l’indexation plus rigoureuse, et par conséquent de meilleure qualité. Par exemple, si le mot « restauration » isolé dans le lexique français n’a pas de référence bien définie, le descripteur « restauration » en relation de spécificité avec le descripteur « architecture » permet, lui, de désigner un objet du monde (exemple issu de « L’indexation d’aujourd’hui » par Muriel Amar). Le thésaurus permet ici de donner du sens à une notion qui n’est normalement pas importante dans un domaine général, mais qui l’est dans un domaine spécialisé.
2. Exemple d’algorithme d’indexation : Kea++
KEA++ (Keyphrase Extraction Algorithm) est un algorithme permettant d’extraire les expressions-clés d’un document texte à l’aide d’informations sémantiques issues de vocabulaires contrôlés tels que des dictionnaires, des thésaurus ou des listes de termes. On remarque que les vocabulaires contrôlés ont la possibilité d’être au format SKOS*.
KEA++ est implémenté en Java et est multiplateforme. Celui-ci est un logiciel open-source distribué par GNU General Public License[11].
Le schéma ci-dessous explique le fonctionnement de l’algorithme KEA++.
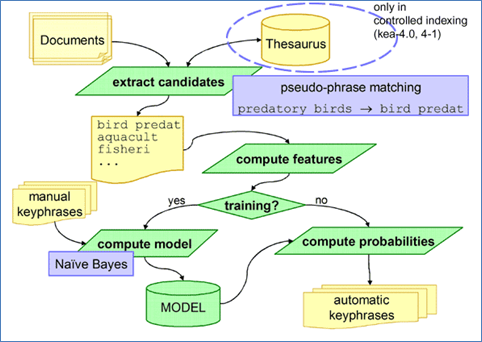
Figure 14: Schéma explicatif du fonctionnement de KEA++ (Source : http://www.nzdl.org/)
L’extraction des expressions-clés par l’algorithme KEA++ se fait selon les étapes suivantes :
1. Documents – L’algorithme prend en compte un dossier et récupère tous les documents textes existants. Des formats normalisés peuvent être pris en compte comme par exemple MODS*.
La langue par défaut est l’anglais, mais d’autres langues peuvent être prises en compte si on dispose d’un outil de racinisation.
2. Utilisation du vocabulaire contrôlé – L’algorithme fait la correspondance entre le vocabulaire contrôlé (exemples : thésaurus, ontologie…) et les documents que l’on souhaite indexer.
Le framework Jena[12] est utilisé pour exploiter le vocabulaire contrôlé.
3. Extraire les candidats – Durant cette étape, KEA++ extrait les expressions de taille prédéfinie (c’est-à-dire de 1 à 3 mots) qui ne commencent pas ou ne se terminent pas par un mot d’arrêt. La liste des mots d’arrêt (appelée anti-lexique ou stop words) contient 425 mots de type conjonctions, articles, prépositions, pronoms, adjectifs, adverbes, verbes irréguliers.
Dans le cas où on possède un vocabulaire contrôlé, l’algorithme ne collecte que les termes qui figurent dans celui-ci. Les mots d’arrêt sont enlevés du document et les mots restants sont racinisés puis ordonnés.
4. Calculer les valeurs constantes – Pour chaque expression candidate, KEA++ calcule 4 valeurs constantes :
- TFxIDF (cf A.1)d) Pondération tf-idf) mesure la fréquence de l’expression candidate dans le document étudié avec sa fréquence d’utilisation dans tous les documents du dossier. Les expressions candidates ayant une grande valeur de TFxIDF ont plus de chance d’être des expressions-clés.
- La première occurrence correspond au nombre de mots qui précèdent l’expression candidate divisé par le nombre de mots dans le document. Le résultat est compris entre 0 et 1 et permet de connaître la position de l’expression candidate dans le document. Dans le cas où celle-ci apparaît en début ou fin de document, elle a plus de chance d’être une expression-clé.
- La longueur de l’expression candidate est le nombre de mots qui la compose. Les expressions à deux mots sont généralement préférées pour l’indexation.
- Le degré du nœud d’une expression candidate correspond au nombre d’expressions de la liste des candidats qui est sémantiquement reliée à celle-ci. Ce nombre est calculé grâce au vocabulaire contrôlé. Les expressions ayant un haut degré ont plus de chance d’être des expressions-clés.
5. Construire le modèle - Avant de pouvoir extraire les expressions-clés d’un document, l’algorithme KEA++ a tout d’abord besoin de créer un modèle donnant des indications sur la stratégie d’indexation manuelle de documents. Pour ce faire, pour chaque document du répertoire, il faut qu’il y ait un fichier .key et son expression correspondante dans ce document. Ce fichier doit contenir les expressions-clés qui ont été données manuellement comme instances positives et tous les mots restants comme instances négatives. En analysant ensuite les valeurs constantes (4.) pour les candidats positifs et négatifs, un modèle est calculé : il contient la distribution des valeurs constantes pour chaque mot.
6. Extraire les expressions-clés – Pendant l’extraction des expressions-clés dans le document à étudier, KEA++ prend le modèle (5.) et les valeurs constantes (4.) pour chaque expression candidate et calcule la probabilité qu’elle soit une expression-clé en utilisant le théorème de Bayes. Les expressions ayant les meilleures probabilités sont sélectionnées pour appartenir à la liste des expressions-clés. L’utilisateur peut spécifier le nombre d’expressions-clés qu’il souhaite sélectionner.
En résumé, un des avantages principaux de cet algorithme d’indexation est qu’il est possible d’utiliser d’un vocabulaire contrôlé, ce qui permet d’éliminer les expressions incorrectes ou dépourvues de sens. De plus, la performance de cet algorithme ne dépend pas de la taille du vocabulaire contrôlé.
C. Méthodes d'indexation étendues avec référentiels
1. Principe
·
·
·
·
·
·
·
·
·
2. Exemple d’algorithme d’indexation : Maui
Maui est un algorithme permettant d’extraire les expressions-clés d’un document texte à l’aide d’informations sémantiques issues de Wikipédia mais aussi de vocabulaires contrôlés. Nous allons nous intéresser uniquement à l’utilisation de Wikipédia comme outil d’indexation.
Maui est implémenté en Java et est multiplateforme. Celui-ci est un logiciel open-source distribuée par GNU General Public License[13].
L’extraction des expressions-clés par l’algorithme de Maui se fait selon les étapes suivantes :
1. Documents – L’algorithme prend en compte un dossier et récupère tous les documents textes existants. La langue par défaut est l’anglais, mais d’autres langues peuvent être prises en compte si on dispose d’un outil de racinisation.
2. Générer les candidats – L’algorithme identifie les expressions candidates dans le document donné à l’aide de Wikipédia, qui est utilisé ici comme un vocabulaire contrôlé. Les candidats générés correspondent à des termes qui figurent dans Wikipédia.
L’outil Wikipedia Miner [14]est utilisé pour accéder au contenu de Wikipédia.
3. Filtrer les candidats – L’algorithme analyse les caractéristiques de chaque candidat pour faire ressortir les candidats les plus pertinents. Voici quelques caractéristiques analysées lors de cette étape :
- Les fréquences, comme la fréquence de l’expression candidate TFxIDF (cf A.1)d) Pondération tf-idf)
- Les occurrences et les positions de l’expression dans le document. On cherche ici quand apparaît la première et la dernière occurrence de l’expression et on regarde si toutes ses occurrences sont étendues dans tout le document. Une expression qui apparaît dès le début du document et qui se répète tout au long de celui-ci a plus de chance d’être une expression-clé.
- La longueur de l’expression candidate est le nombre de mots qui la compose. Les expressions à deux mots sont généralement préférées pour l’indexation.
- Le degré du nœud d’une expression candidate correspond au nombre d’expressions de la liste des candidats qui est sémantiquement reliée à celle-ci. Ce nombre est calculé en utilisant les statistiques du corpus de Wikipédia.
- La probabilité pour l’expression candidate d’être une expression-clé en se basant sur Wikipédia.
4. Construire le modèle et extraire les expressions-clés – Ces étapes sont similaires à celles de l’algorithme Kea++.
En résumé, cet algorithme offre la possibilité pour une institution ne disposant pas de vocabulaire contrôlé d’indexer son fonds documentaire avec l’aide du contenu de Wikipédia pour obtenir des résultats plus fiables.
Plus d’informations dans le document « Topic Indexing with Wikipedia » écrit par Olena Medelyan, Ian H. Witten et David Milne.
III. Solutions existantes
A. Moteurs de recherche Internet
Les moteurs de recherche web sont aujourd’hui devenus incontournables, plus de 17 milliards de recherches sont effectuées chaque mois aux Etats-Unis et ce chiffre ne cessent de croitre (voir statistiques ci-dessous). Nous allons dans cette partie présenter quelques-uns des principaux moteurs de recherche internet.
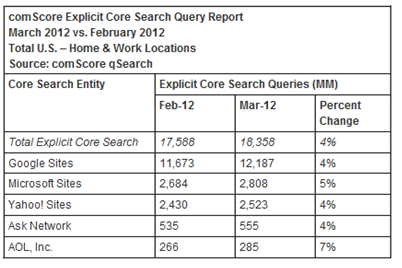
Figure 15 : Statistiques des recherches internet aux Etats-Unis pour les mois de Février et Mars 2012 (Source : http://www.comscore.com/fre/Press_Events/Press_Releases/2012/4/comScore_Releases_March_2012_U.S._Search_Engine_Rankings)
1. Google
Google, acteur mondial de la recherche internet, utilise de son côté des robots d’indexation appelés Googlebots dans le but de rechercher et d’indexer des pages web. Ses robots d’indexation utilisent un processus basé sur des algorithmes permettant de déterminer les sites à explorer, la fréquence d'exploration et le nombre de pages à extraire de chaque site.
Bien que les moteurs de recherche soient en grande partie axés sur les contenus textuels, Google est capable d’indexer la plupart des types de ressources, voici les principaux : documents Office et Open Office, des langages de programmation courant structuré et objet tels que le C, C++, C#, Java….etc. Il prend également en compte les fichiers de types XML, PDF…
Google a sorti différents algorithmes dont Caffeine en 2010. Cet algorithme permet de mettre à jour les index en quasi-temps réel, alors qu’auparavant ceux-ci n’étaient mis à jour que tous les mois.
En 2011, Google sort un nouvel algorithme : Panda. Cet algorithme vise à dissocier les contenus originaux de ceux des sites qui dupliquent du contenu ou qui se contentent d'en reprendre une partie. Avec cette innovation, Google veut pousser les éditeurs à proposer du contenu original.
Enfin depuis la sortie de Panda, le système de recherche et d’indexation de Google ne cesse d’évoluer, la géolocalisation est de plus en plus mise en avant et l’indexation de médias (vidéos, photos…) ne cessent de prendre de l’ampleur.
2. Bing
Bing est le devenu le 2ème moteur de recherche le plus fréquenté. Il appartient au groupe Microsoft.
Microsoft continue d’améliorer l'indexation et la pertinence des résultats de son moteur de recherche grâce une mise à jour qui ressemble à Caffeine de Google. Son nouvel algorithme s’appelle Tiger. Le but de cette modification est de rendre l’indexation plus rapide et avoir des résultats plus pertinents pour l’utilisateur.
Tiger devrait réduire les coûts de fonctionnement du moteur de Microsoft. Le processus de déploiement a commencé en août 2011, et devrait s'achever cette année.
3. Yahoo
Yahoo est le 3ème moteur de recherche le plus utilisé au niveau mondial.
La technologie de Yahoo a migré sur les plateformes de Bing. Donc Microsoft fournit désormais à Yahoo les mêmes résultats que ceux diffusés sur Bing.
Cela a donc pour conséquence le fait que les critères de positionnement de Bing sont les mêmes que ceux de Yahoo. Il suffit donc de prendre en compte ces critères pour apparaître sur les deux moteurs de recherche.
4. De nouveaux entrants
De nouveaux moteurs de recherche internet tentent de se faire une place au milieu de ces grands noms. C'est notamment le cas de Volunia.
Volunia, sorti le 7 février 2012, est un nouveau moteur de recherche créé par le fondateur de l’ancien algorithme sur lequel s'est basé Google, Massimo Marchiori.
Le concept de ce moteur de recherche semble être bien différent de ce qui se passe du côté de Google ou Bing car il se base en grande partie sur les communautés d’utilisateurs.
Chaque utilisateur a la possibilité de laisser un commentaire sur les résultats d’une recherche. Il lui est également possible de communiquer avec les personnes présentes en même temps que lui sur une même page. Celui-ci peut se créer alors un réseau social directement sur le moteur de recherche.
Pour agrémenter les recherches, il est possible de réaliser des représentations cartographique ou simple des résultats afin de représenter l’arborescence du site. Il propose également d'autres liens vers des pages et des sites proches du résultat en question.
Néanmoins, il est encore difficile de savoir si Volunia s’imposer face à Bing et Google.
Cependant, à l’heure actuelle (d’après le peu d’utilisateurs possédant un accès privé pour le test de la version Béta) les résultats retournés par Volunia sont très différents et semblent moins pertinent que ceux retournés lors d’une recherche sur google, par exemple.
Il nous semble intéressant de continuer à suivre l'évolution de l'algorithme utilisé par Volunia.
Voici une impression d’écran prise sur le blog Abondance permettant de voir un aperçu des cartographies proposées par ce nouvel outil :
Figure 16: Carte visuelle du blog Abondance
B. Solutions d’indexation et de recherche d’information
Beaucoup d’entreprises fournissent des solutions d’indexation et de recherche plus ou moins complètes. Le client doit choisir la solution qui lui convient en fonction de ses besoins réels :
· Type d’indexation souhaité,
· Types de fichiers à indexer,
· Appui sur un référentiel ou non,
· Quantité d’information,
· Moyen d’accès à l’information…
En outre les différentes solutions proposées sur le marché peuvent être propriétaire ou Open Source. En effet lors de ces dernières années, le monde de l’Open Source s’est fait de plus en plus présent et spécialisé dans le métier de la gestion documentaire. Bien que les entreprises mettent à disposition des logiciels en Open source, elles gagnent de l’argent en faisant du consulting.
Nous allons voir au travers de cette partie quelques-uns de ces fournisseurs de solutions d’indexation et de recherche ainsi que les produits qu’ils proposent en organisant notre présentation de la manière suivant :
· Indexation à partir de documents papiers
· Logiciel permettant l’extraction de métadonnées
· Moteur de recherche pour entreprise
· Solutions d’indexation plus étoffées
1. Indexation à partir de documents papiers
Un enjeu majeur dans la gestion des documents est l’indexation de documents non-numériques. C’est devenu un élément important de l’indexation, car de plus en plus d’entreprises cherchent à indexer des documents papiers.
Diadeis Numérisation fait de la recherche qui a pour but d'améliorer de la qualité des textes issus de la numérisation. Lorsque ce projet sera abouti, on peut espérer que les textes issus de la numérisation seront de meilleures qualités. Et par conséquent, cela facilitera la lecture automatique de documents. Ce qui permettra lors d’une indexation documentaire d’éviter d’avoir à ressaisir l’information du document.
OpenText a sorti la solution Capture for Microsoft SharePoint afin de numériser des documents. Ensuite ces documents seront déposer le SharePoint de l’entreprise. Cette solution permet :
· de scanner,
· de numériser,
· d’indexer entièrement des documents papier.
L’objectif de cette nouvelle solution est de permettre aux entreprises de réduire la quantité de documents papier au sein de l’entreprise, mais aussi rendre plus facile la recherche documentaire. Le document numérisé et indexé sera transférer sur le SharePoint qui rendra les échanges d’information plus facile.
2. Extraction des métadonnées
Certains logiciels permettent l’extraction des métadonnées comme Entity Extraction, une solution propriétaire de Pingar, qui permet d'extraire des métadonnées (mots clés, lieu, date, URL, etc.) depuis un texte. Il supporte 6 langues : anglais, français, allemand, espagnol, chinois et japonais. Il peut également être utilisé comme extension de SharePoint que nous avons vu précédemment.
Il existe aussi des solutions Open Source pour extraire les métadonnées d’un document. On peut citer Tika qui est un logiciel développé par l'Apache Software Foundation. Il est capable d’extraire des métadonnées sur plusieurs types de document comme des documents texte (HTLM, XLM ou Microsoft Office…), différent format image, audio et vidéo.
3. Les moteurs de recherche en entreprise
Les moteurs de recherche sont un élément clé de la recherche documentaire. Ils permettent de retrouver un document en fonction de mots clés ou métadonnées
Onyme, qui a mené des recherches sur l’analyse sémantique en partenariat avec le CNRS, propose par exemple un moteur d’analyse sémantique qui a pour but d’analyser la langue. Ce moteur est composé d’un correcteur orthographique et d’un outil de recherche de synonymes qui permet d’étendre la recherche. Ensuite le moteur d’analyse sémantique calcule la distance entre la recherche et les données à disposition.
Voici maintenant deux moteurs de recherche Open source.
Solr est un logiciel développé dans le cadre du projet Apache Lucene. Ce logiciel utilise Lucene JAVA qui est une bibliothèque JAVA très performante, permettant de faire de la recherche.
Les principales caractéristiques sont :
· Saisie intuitive (propose des mots à l’utilisateur)
· Approximation orthographique (peut corriger automatique les fautes d’orthographe)
· Gestion de la synonymie
· Une optimisation des requêtes
· Ignore les mots vides pendant la recherche
4. Des solutions d’indexation plus étoffées
Nous avons jusqu’à maintenant vu des logiciels qui font une partie de l’indexation ou de la recherche d’information. Nous allons présenter des entreprises qui fournissent des solutions complètes plus complètes. Ces solutions s’appuient parfois sur des logiciels présentés auparavant.
Open Wide est un des acteurs importants dans l’intégration et l’exploitation des logiciels libres en France. Open Wide propose différentes solutions de gestion documentaire Open source
Voici les fonctionnalités proposées par le logiciel open source d’Open Wide concernant l’indexation documentaire :
· Intégration de documents papier nécessitant une transformation au format électronique
· Intégration de documents numériques (Documents, images, vidéos, mails...)
· Indexation et description du contenu du document facilitant sa recherche (auteur, titre, date, contenu...).
Même si les logiciels d’Open Wide sont gratuits, l’entreprise propose ses services pour aider à la prise en main du logiciel.
DOCULIBRE est une entreprise spécialiste de l’information. Tous les logiciels que l’entreprise propose sont libres. Les offres proposées par Doculibre s’étendent sur les domaines des moteurs de recherche, de la gestion des documents, mais aussi sur le Text Mining.
Au niveau des moteurs de recherche, l’entreprise propose :
· Constellio
· Apache Solr.
Voici une description de Constellio :
Constellio se base sur Google Search Appliance et Apache Solr. Comme il est basé sur le moteur le moteur de recherche Solr, il reprend les mêmes caractéristiques. Cependant il possède des fonctionnalités supplémentaires.
Ces fonctionnalités est disponible en annexe 3.
Voici quelques caractéristiques :
· Plusieurs langues disponibles
· Compatible avec plusieurs formats (PDF, HTML, XML…)
· Compatible avec plusieurs bases de données (mysql, Oracle…)
Ce logiciel peut indexer avec des thésaurus (grâce à Kea) et détecter automatiquement la langue.
Pour la gestion des documents, il y a le choix entre 5 logiciels différents. On peut citer Alfresco ou Nuxeo.
Au niveau du Text Mining (traitement automatisé d'une base de données textuelle), Doculibre possède des technologies basées sur le logiciel Weka permettant d’associer des thésaurus à un document.
Weka est un logiciel libre diffusé par GNU General Public. Weka contient plusieurs outils pour les traitements des données (la classification, la régression, le clustering, règles d'association…). Il est également bien adapté pour le développement de nouveaux systèmes d'apprentissage machine.
Google, acteur mondial de la recherche internet, propose des solutions propriétaires d’indexation et de recherche d’information aux entreprises :
· Google propose en partenariat avec Gpartner un moteur de recherche interne à l’entreprise,, permettant d’indexer tout type de document en quantité très importante et d’y accéder très simplement comme sur un moteur de recherche classique
·
Mondeca, éditeur français spécialisé dans la gestion d'ontologies et le web sémantique propose un logiciel basé sur les langages courants du Web Sémantique, à savoir XML, URI, RDF, SKOS, OWL, API... et destiné à la gestion des thésaurus, bases de connaissances, dictionnaires de métadonnées.
Mondeca propose également des solutions permettant d’accéder à des bases de connaissances et offrant des services avancés de recherche, navigation et suggestion automatisée.
Les produits proposés par Mondeca sont exploités par de grandes enseignes telles que Lexis Nexis, Thomson Scientific, Office des Publications de la Commission Européenne, PSA, Lafarge, Voyages SNCF.
Voir la description des fonctionnalités du logiciel Mondeca (Annexe 1).
Témis, un éditeur international de logiciels spécialisés dans les produits de fouille de textes, met à disposition de ses clients des logiciels permettant de transformer un texte en données analysables afin de classer les documents ou d’en extraire de l’information. Leur solution, Luxid, est structurée en trois couches applicatives :
· Luxid® Content Pipeline permettant la collecte de contenus des centres d’intérêt définis.
· La plateforme Luxid® Content Enrichment permettant d’extraire des métadonnées de type entités, relations, catégories, concepts, sentiments et attributs.
· Les outils de recherche, de découverte et de partage de Luxid® permettant la recherche, l’analyse et l’extraction de l’information contenu dans la base de connaissance
Voir la description des fonctionnalités du logiciel (Annexe 2).
Exalead est une entreprise fournissant des logiciels de recherche et d’accès d’information. Elle propose de mettre en place au sein des entreprises des Search Based Applications (SBA), sans toutefois remplacer les systèmes d’informations. Ils proposent la mise en place des SBA car les systèmes d’information actuels sont très performants au niveau de la mise à jour et du stockage des données, mais ils le sont beaucoup moins pour la visualisation de ces dernières. Les SBA permettent donc de rendre accessible l’information aux utilisateurs en leur donnant un sens. D’après Exalead, les SBA permettent d’améliorer les performances par 100 par rapport à un autre système.
Ontotext est un contributeur aux plates-formes open source. Il est efficace dans les domaines du développement d’outils sur les technologies sémantiques, l’optimisation des performances, l’intégration de donnée.
Ontotext utilise plusieurs technologies telles que KIM Platform, OWLIM, FactForge ou ORDI. OWLIM par exemple est une famille de référentiels sémantiques, ORDI signifie représentation ontologique et intégration de données. Cette technologique vise la neutralité du langage ontologique et l’intégration des bases de données. FactForge permet aux utilisateurs de trouver des ressources et des faits sur la sémantique des données, et fournit une méthode efficace de recherche de données.
Conclusion
Une bonne gestion de l’information est primordiale pour conserver les connaissances accumulées au fil des années. Cependant, le plus important n’est pas d’être capable de stocker toutes ces données, mais de retrouver l’information qui nous intéresse. C’est pour cette raison qu’il est alors indispensable d’indexer correctement les documents. L’indexation, qui consiste à extraire les métadonnées d’un document, permet de récupérer les informations qui le décrivent. Ces différentes données vont permettre de retrouver les documents les plus pertinents lors d’une recherche effectuée par un utilisateur. De nombreuses méthodes d’indexation ont été mises en place, qu’elles soient manuelles, semi-automatiques ou automatiques.
Avec l’augmentation croissante de l’information, il a été nécessaire de concevoir des outils pour faciliter les recherches de documents. C’est pour cette raison que des référentiels ont été créés (comme les thésaurus). Ces derniers permettent, entre autres, d’améliorer la recherche de l’utilisateur en palliant les différences de vocabulaire entre la personne qui recherche et la personne qui indexe. Ils permettent aussi d’élargir les recherches de l’utilisateur en proposant davantage de résultats.
Afin de répondre au besoin de la gestion de l’information en entreprise, de nombreuses sociétés se sont développées dans ce secteur. Elles fournissent des solutions d’indexation plus ou moins complètes, utilisant ou non des référentiels. Ces différentes solutions se basent sur des algorithmes toujours plus performants et en constante évolution. Il existe également des organismes de normalisation qui sont des acteurs importants de l’indexation, car ils créent de nouvelles normes qui permettent d’unifier, entre autres, les méthodes d’indexation.
Nous constatons que l’indexation est un enjeu important au sein des entreprises et que ce domaine est en perpétuelle évolution afin d’optimiser la recherche documentaire. Avec l’amélioration des techniques d’indexation, la recherche d’information sera encore plus rapide avec des résultats de recherche toujours plus pertinents qui correspondront parfaitement à la requête de l’utilisateur. Cela est possible grâce au progrès au niveau de la recherche sémantique.
Nous pensons qu’il y aura encore des évolutions dans ce domaine au cours des années à venir.
L’augmentation du nombre d’entreprises spécialisées dans l’indexation nous permet de penser qu’il y aura de plus en plus de solutions, avec des logiciels toujours plus performants. Au cours de notre veille technologique, nous avons pu constater, qu’il y a de nombreux logiciels qui sont mis sur le marché. Un secteur de l’indexation en plein essor est l’indexation des documents papiers. C’est un enjeu majeur pour l’indexation documentaire. En effet, les entreprises cherchent à numériser ses documents afin de faciliter leurs recherches documentaires. Ces documents numérisés sont placés sur un espace de partage. Donc les documents sont directement accessibles par tous les employés.
Une seconde évolution est l’amélioration de l’utilisation des folksonomies. À l’heure actuelle cette indexation collaborative ne s’appuie pas sur un vocabulaire contrôlé ce qui représente un avantage, car l’utilisateur peut utiliser les mots de son choix pour décrire un document, mais c’est aussi un point faible, car si la personne qui indexe fait une erreur, le document est alors plus difficilement retrouvable. Nous pensons donc que les folksonomies pourraient à terme être utilisées avec un référentiel, ce qui permettrait d’éviter les problèmes liés aux fautes d’orthographe, aux verbes conjugués, aux singuliers pluriel etc. Cependant ce référentiel ne devrait pas être contraignant pour les utilisateurs et devrait leur permettre de continuer à utiliser leur propre vocabulaire. Ainsi par exemple, les verbes conjugués saisis par l’utilisateur pourraient être reconnus automatiquement et transformés en leur lemme sans aucune intervention de l’indexeur. L’objectif recherché serait également de pouvoir hiérarchiser ou du moins catégoriser les tags et de proposer automatiquement des tags à l’utilisateur pour l’aider à indexer. Une autre piste d’amélioration concerne la reconnaissance de la pertinence des tags pour supprimer automatiquement les tags jugés non pertinents. Avec ces améliorations, l’indexation collaborative devrait être de meilleure qualité.
Une troisième évolution est l’amélioration de l’indexation automatique. Actuellement il existe de nombreuses recherches sur ce domaine qui donnent naissance à de nombreux algorithmes. Nous pensons donc que l’indexation automatique va encore progresser pour être encore plus performante. Cette indexation prendra en compte la sémantique des mots afin de permettre une indexation optimale.
Glossaire
Descripteurs
Les descripteurs sont des mots-clés, des termes qui servent à traduire des concepts, à caractériser l'information contenue dans un document. Ils servent à indexer les documents pour en faciliter la recherche.
D'après la définition de l'AFNOR de 1987, un descripteur est "choisi parmi un ensemble de termes équivalents pour représenter sans ambiguïté une notion apparaissant dans un document ou dans une demande de recherche documentaire."
Contrairement à un mot-clé, c'est un terme issu d'un vocabulaire contrôlé. Les descripteurs sont bien souvent normalisés dans un thésaurus.
Folksonomie
Une folksonomie est un système de classification collaborative dont le vocabulaire n’est ni contrôlé ni organisé. Ce type d’indexation n’est pas réalisé par des documentalistes mais par des non-spécialistes, par tout un chacun. Les termes utilisés pour décrire les documents sont souvent appelés mots-clés, tags ou étiquettes. N’étant pas du tout prédéfinis, ces termes dépendront de l’indexeur. Un même document sera donc décrit avec des mots-clés différents d’un indexeur à l’autre. La recherche d’information sera donc réalisée en passant d’un mot-clé à un autre, d’un synonyme à un autre. La recherche peut paraitre plus longue mais l’avantage c’est que l’abondance de tags pour un même document augmente les chances que les termes utilisés pour indexer un document correspondent à ceux utilisés par la personne qui réalise la recherche.
HAL (Hyperspace Analogue To Language)
Le HAL est une méthode statistique pour déterminer les mots liés avec d’autres dans un corpus. Nous allons l’illustrer sur cet exemple tiré du blog Onyme[15] :
· Doc 1 : « Sarkozy débute la campagne présidentielle UMP »
· Doc 2 : « Sarkozy affronte Hollande »
· Doc 3 : « Hollande a été désigné pour la présidentielle PS »
· Doc 4 : « Il y a des tracteurs en campagne »
Voici le processus d’indexation du HAL :
1. Filtrage des mots – Les documents sont épurés des mots vides : « la », « la », « a », « été », « pour », « il », « y », « des », « en ». Cette étape se fait via une liste stop words.
2. Matrice des cooccurrences – Le HAL calcule dans un premier temps une matrice de cooccurrence. Cette matrice contient des poids qui indiquent si deux mots sont cooccurrents dans le texte. Prenons le document Doc 1. Les mots « Sarkozy » et « débute » sont voisins (côte à côte) dans le texte : ils sont comptés comme cooccurrents. « campagne » est le voisin du voisin de « Sarkozy » : ils seront comptés comme cooccurrents mais avec un poids plus faible que le couple précédent. En pratique voici la formule qui permet de calculer le poids :
Poids = taille de la fenêtre + 1 – distance entre les deux mots
La taille de la fenêtre est la distance maximale acceptée pour le calcul du poids.
Voici la matrice de cooccurrence de notre corpus en prenant une fenêtre de taille 2 :
|
|
Sarkozy |
débute |
campagne |
présidentielle |
UMP |
affronte |
Hollande |
désigné |
PS |
tracteurs |
|
Sarkozy |
|
|
|
|
|
|
|
|
|
|
|
Débute |
2 |
|
|
|
|
|
|
|
|
|
|
campagne |
1 |
2 |
|
|
|
|
|
|
|
2 |
|
présidentielle |
|
1 |
2 |
|
|
|
1 |
2 |
|
|
|
UMP |
|
|
1 |
2 |
|
|
|
|
|
|
|
Affronte |
2 |
|
|
|
|
|
|
|
|
|
|
Hollande |
1 |
|
|
|
|
2 |
|
|
|
|
|
Désigné |
|
|
|
|
|
|
2 |
|
|
|
|
PS |
|
|
|
2 |
|
|
|
1 |
|
|
|
tracteurs |
|
|
|
|
|
|
|
|
|
|
Figure 17 Matrice de cooccurrence de notre corpus (blog.onyme.com)
Les lignes de cette matrice sont appelées contexte gauche du mot de la ligne : « le degré avec lequel chaque mot du lexique précède le mot de la ligne ».
Les colonnes de cette matrice sont appelées contexte droit du mot de la colonne : « le degré avec lequel chaque mot du lexique suit le mot de la colonne ».
3. Calcul des vecteurs de cooccurrence
On peut déduire des vecteurs de cooccurrence via la matrice précédente. Un vecteur correspond à l’union des contextes gauches et droits d’un mot.
4. Calcul des similarités entre les vecteurs de cooccurrence - On peut ensuite calculer les distances entre les vecteurs de cooccurrence grâce à la distance du cosinus[16].
Le résultat de ces calculs montre par exemple que la similarité entre « UMP » et « PS » est de 80% : sim(UMP, PS) = 4 / (rac(5) * rac(5)) = 0,8.
Il existe d’autres algorithmes du même genre : LSI (Indexation Sémantique Latente), (PLSI (Indexation Sémantique Latente Probalistique), LDA (Latest Dirichlet Allocation).
Liste Rameau
RAMEAU est le vocabulaire d’indexation utilisé par un grand nombre de bibliothèques francophones. Il est utilisé par la Bibliothèque Nationale de France, par un nombre important de bibliothèques spécialisées ainsi que dans les bibliothèques municipales et départementales. Il est aussi le langage d’indexation de bibliothèques à l’étranger, telles que les bibliothèques publiques de la Communauté française de Belgique ou la Bibliothèque Nationale de Tunisie.
Les mots contenus dans la liste RAMEAU comportent les liens classiques de tout thésaurus (liens associatifs, génériques et spécifiques). Mais contrairement à un thésaurus qui est spécialisé dans un domaine précis (comme l’archéologie, l’architecture…), RAMEAU couvre toutes les disciplines scientifiques.
L’avantage de l’utilisation de la liste RAMEAU, en plus de recouvrir plusieurs domaines, est la pré-coordination des mots de l’encyclopédie de RAMEAU. La pré-coordination signifie que l’ordre des mots lors de la saisie est important lorsque l’on fait une recherche. Par exemple, « Droit – Informatique » se rapportera à « l’informatique juridique » tandis que la recherche « Informatique – Droit » désignera le « droit de l’informatique ».
Le second élément de la recherche sert à indiquer le contexte d’emploi du premier, information indispensable dans un environnement encyclopédique. L’ordre des mots de la recherche est, dans RAMEAU, porteur de l’information contrairement à un thésaurus où la recherche précédente donnerait le même résultat, car l’ordre des mots n’a pas d’importance.
Métadonnées
Une métadonnée est une donnée qui décrit une autre donnée dont le support peut être physique ou numérique.
Une notice bibliographique peut être considérée comme une métadonnée puisqu’elle décrit un document qui est une donnée.
D’une manière générale, il existe trois grands types de métadonnées :
· Les métadonnées qui décrivent une source pour permettre son identification et sa recherche. Ces métadonnées peuvent ainsi par exemple donner des renseignements sur le titre, le nom de l’auteur ou fournir un résumé du document. Ce type de métadonnées facilite la recherche documentaire.
· Les métadonnées qui renseignent sur la structure d’un document avec par exemple une explication de l’agencement des chapitres d’un livre.
· Les métadonnées qui aident à l’administration avec par exemple des renseignements concernant les dates de création du document, son type, les personnes qui sont autorisée à accéder à cette ressource, comment conserver et stocker cette information, etc. Ces métadonnées sont utiles pour gérer les ressources d’information.
En 1995, un atelier fut organisé à Dublin concernant les métadonnées donnant naissance à une norme sur les métadonnées (ISO 15836-2003, RFC 5013). L’ensemble des métadonnées traitées durant cet atelier sont appelées métadonnées Dublin Core et sont cataloguées par la Dublin Core Metadata Initiative (DCMI).
MODS
MODS (Metadata Object Description Schema) est un modèle destiné au traitement de données bibliographiques, en particulier dans le contexte des bibliothèques, mais peut être élargi à d'autres usages. Ce modèle permet de décrire des ressources très diverses telles que des textes, images, partitions, sites Web …
Il a été développé en 2002 par la Bibliothèque du Congrès[17]. Celle-ci en assure la gestion et met à disposition des utilisateurs de MODS un schéma XML (qui est une recommandation du W3C), dont la version actuelle est la 3.4.
Le standard MODS est utilisé dans de nombreuses bibliothèques à travers le monde.
Pour convertir un document au format MODS, des normes sont à respecter. Chaque information concernant ce document doit être disposée entre les balises qui lui correspondent.
Voici une liste des balises principales caractérisant un document respectant la norme MODS, ainsi qu’une description de celles-ci:
· titleInfo : élément englobant qui regroupe les informations relatives au(x) titre(s) de la ressource. Les éléments constitutifs du titre sont encodés dans des éléments spécifiques du type title, subTitle…
· name : informations identifiant une personne ou une collectivité et précisant son rôle (responsabilité). Cet élément contient des éléments plus spécifiques du type namePart, description…
- language : langue(s) sous une forme textuelle ou codée.
- abstract : résumé.
- subject : élément englobant qui regroupe les sujets. Il peut contenir des éléments plus spécifiques du type topic, temporal, titleInfo…
- identifier : identifiant normalisé (ISBN, URI par exemple)
- location : institution qui conserve et/ou met à disposition la ressource décrite (exemplaire)
Ces différentes appellations permettent de respecter le modèle MODS et d’obtenir un format universel, facilitant par conséquent une exploitation de ces documents.
Exemple
Le document ci-dessous présente un exemple de notice d’un travail concernant l’histoire du Canada, complété par le fichier MODS correspondant.

Figure 18: Notice d'une étude à propos de l'histoire du Canada (http://www.canadiana.org)
Extrait du fichier MODS correspondant :
<modsCollection>
<mods>
<location>
<url>http://www.canadiana.org/ECO/ItemRecord/40145</url>
</location>
<titleInfo>
<title>On Algonkin names for man </title> [champ « Title » de la notice]
</titleInfo>
<name>
<namePart>Trumbull, J. Hammond</namePart> [champ « Principal Author »]
</name>
<abstract>Title from title screen."[From the Transactions of the American Philological Association, 1871]." </abstract> [champ « General Note »]
<subject>
<topic>Algonkin language -- Etymology.</topic>
</subject>
<subject>
<topic>Algonquin (Langue) -- Étymologie.</topic>
</subject>
<typeOfResource>text</typeOfResource>
<recordInfo>
<recordContentSource>Canadiana.org</recordContentSource>
</recordInfo>
</mods>
(…)
</modsCollection>
NB : Les notes en rouge ont été rajoutées pour une meilleure compréhension
Notice documentaire
Une notice documentaire est une fiche qui décrit un document. Elle comporte un ensemble d'indications permettant d'identifier, de localiser et de décrire sommairement le document en question.
Une notice peut être décrite de façon normalisée grâce à des langages de description de schéma (exemple : MODS*).
Ontologie
D’après Karl Dubost[18] « une ontologie correspond […] à un vocabulaire contrôlé et organisé et à la formalisation explicite des relations créées entre les différents termes du vocabulaire. »
Par exemple si un terme est défini comme étant une sous-catégorie d’un autre terme alors il existe une relation entre ces deux termes.
D’après Karl Dubost « Pour réaliser cette formalisation, on peut utiliser un langage particulier. Un des langages utilisés pour décrire les relations entre les différents termes d'un vocabulaire s'appelle RDF. » Le langage SKOS permet également de développer les ontologies.
D’après Domingos Ruiz Lepores[19], les ontologies peuvent être considérées « comme un prolongement du thésaurus et une manière de le rendre viable et fonctionnel sur le web. Dès lors, une ontologie serait une version de thésaurus bien plus sophistiquée, avec une vision pluridimensionnelle des termes. »
RDF (Resource Definition Framework)
D’après le site descripteurs[20], « RDF (Resource Definition Framework) est un langage qui sert de cadre formel pour décrire des "ressources". Dans le contexte RDF, tout ce qui est manipulé s’appelle ressource. À chaque élément décrit correspond un triplet RDF qui définit précisément cet élément. Cet ensemble d’information peut alors être traité automatiquement par un programme informatique.
Pour aller plus loin, le triplet recouvre :
· le sujet : la ressource décrite. […]
· le prédicat : propriété ou attribut. […]
· l’objet : valeur pour telle propriété. […] »
Référentiel
D’après le site « guideinformatique.com »[21], un référentiel est une « mise en commun intellectuelle de terminologie, de pratiques ou de règles servant de référence. Le référentiel rassemble ainsi sous un vocabulaire commun (et généralement explicite) toutes les notions que s’échangent les différents services et logiciels de l’entreprise. »
Les référentiels servent de cadre commun et existent sur des supports très variés allant du papier au disque dur en passant par les bandes magnétiques.
Il existe différents types de référentiels :
· Dictionnaires explicatifs/traductifs,
· Encyclopédies,
· Répertoires spécialisés : tables ou recueils où les matières sont rangées dans un ordre qui les rend facile à trouver,
· Annuaires,
· Lexiques : dictionnaires spécialisés reprenant les termes utilisés dans une science ou une technique,
· Thésaurus…
SKOS
SKOS (Simple Knowledge Organisation System ou Système simple d’organisation des connaissances) est un langage de représentation de schémas de concepts, qui recouvre les langages documentaires tels que les thésaurus, classifications, etc.
Son nom a été choisi pour mettre en évidence l’objectif même visé par ce langage : « proposer un système permettant d’exprimer et de gérer des modèles interprétables par les machines dans la perspective du web sémantique. » (Source : Michèle Lénart, la revue « Documentaliste » Volume 44, N° 1, paru le 28 février 2007)
Ce modèle est défini comme « simple » par opposition à d’autres modèles, comme OWL[22], plus à même de représenter des structures sémantiques plus riches telles que les ontologies, mais de ce fait également plus complexes à utiliser.
SKOS est depuis le 18 août 2009, une recommandation du World Wide Web Consortium* (W3C).
Principes de représentation de SKOS
Le formalisme de représentation utilisé par SKOS repose sur les graphes RDF. Le concept constitue le centre du graphe auquel peuvent notamment être attachés en tant que propriétés RDF :
- les indications portant sur le concept lui-même :
- des termes préférentiels ou alternatifs, les équivalents dans d’autres langues,
- les termes cachés, très pratiques pour gérer des variantes correspondant à des fautes d’orthographes courantes, ce qui permettra de les prendre en compte en recherche sans qu’elles apparaissent en affichage ou en impression du thésaurus,
- la représentation par une image ;
- les différents types de notes : notes de définition et d’application (scope note), exemples, notes historiques, etc. ;
- les relations sémantiques : hiérarchie et association.
Composition de SKOS
L’élément essentiel est le « SKOS Core », ou le noyau de SKOS. Ce terme de noyau est à prendre au sens propre car il s’agit bien des classes et des propriétés de base. Elles peuvent être complétées par les « SKOS Extensions », les extensions de SKOS, qui permettent de:
- représenter les relations de manière plus fine : il est possible, par exemple, de préciser si la nature d’une relation de hiérarchie est de type tout/partie ou classe/instance ;
- préciser certains attributs d’un concept : une note historique, par exemple.
La figure ci-dessous présente un exemple, issu du SKOS, de modèle de représentation d’un concept, complété par le fichier RDF correspondant.
Figure 19: Modèle de représentation du concept Edifice
Extrait du fichier RDF correspondant :
|
<skos:Concept rdf:about="http://frantiq.mom.fr/PACTOLS/concept#17634"> <skos:prefLabel xml:lang="fr">édifice</skos:prefLabel> <skos:altLabel xml:lang="fr">bâtiment</skos:altLabel> <skos:broader rdf:resource="http://frantiq.mom.fr/PACTOLS/concept#13289"/> [architecture] <skos:narrower rdf:resource="http://frantiq.mom.fr/PACTOLS/concept#13685"/> [bât à FM] <skos:narrower rdf:resource="http://frantiq.mom.fr/PACTOLS/concept#13684"/> [bâtiment militaire] <skos:narrower rdf:resource="http://frantiq.mom.fr/PACTOLS/concept#17635"/> [edifice funéraire] <skos:narrower rdf:resource="http://frantiq.mom.fr/PACTOLS/concept#17636"/> [edifice public] <skos:related rdf:resource="http://frantiq.mom.fr/PACTOLS/concept#12243"/> [monuments] <skos:scopeNote xml:lang="fr">Bâtiment important (Rob.)</skos:scopeNote> </skos:Concept> |
NB : Les notes en rouge ont été rajoutées pour une meilleure compréhension
Taxonomie
Par exemple, dans une classification animale, nous aurons les vertébrés, invertébrés et puis sous les vertébrés nous auront les mammifères, les ovipares, etc. Tous ces termes nous permettront de classifier les animaux. On pourra donc dire que les mammifères représentent une sous-catégorie (sous-classe) des vertébrés. »
Les taxonomies permettent de traduire des relations hiérarchiques de type généralisation ou spécialisation entre les descripteurs.
Thésaurus
Un thésaurus est un vocabulaire contrôlé (ensemble de descripteurs) et organisé (ensemble de relations entre les descripteurs) servant à représenter des concepts.
Les relations existantes entre les descripteurs sont des relations d'équivalence (synonymes), des relations de hiérarchisation (spécification ou généralisation) et des relations d'association (du type "relatif à" ou "similaire à").
Ainsi lorsque l’on recherche un mot avec un thésaurus, la recherche s’étendra à tous les mots équivalents, parents et associés. L’utilisateur aura donc plus de chance de trouver un résultat correspondant à sa recherche.
Par exemple un thésaurus reliant « vente » à « production », « voiture » à « véhicule », et « France » à « Europe », permettra pour une question portant sur les ventes de voitures en France de trouver des ressources indexées avec « production » « véhicule » « Europe ».
URI (Uniform Ressource Identifier)
Une URI est un identifiant uniforme de ressource. D’après le site descripteurs, « L’URI est le protocole qui normalise la syntaxe de la chaîne de caractères qui identifie une ressource physique (image, document sur le web) ou abstraite (concepts) ». Une URI doit permettre d’identifier une ressource de manière unique et pérenne sur un réseau (par exemple le web). D’après le site descripteurs, « cet identificateur permet aussi de distinguer des ressources entre elles. Parmi les URI, on peut distinguer: l’URL (Uniform resource locator = Localisation de ressource uniforme) » qui identifie une ressource sur un réseau, la localise et permet d’en obtenir une représentation. Il existe également l’URN (Universal Resource Name = Nom de ressource uniforme) qui identifie la ressource indépendamment de sa localisation. Le code ISBN, qui est l’identifiant unique d’un livre et permet de le retrouver dans n’importe quelle librairie ou bibliothèque dans le monde entier, est aussi une forme d’URI.
Vocabulaire
Le but d’un vocabulaire est d’organiser et de clarifier l’information qui nous entoure. Un vocabulaire est un ensemble de termes définis et partagés par un groupe afin d’échanger de l’information. La signification du vocabulaire est dépendante du groupe qui l'utilise. Il n'y a pas nécessairement d'organisation logique des termes entre eux.
Le glossaire d'un livre est un vocabulaire.
W3C (World Wide Web Consortium)
Le World Wide Web Consortium est un organisme de standardisation qui a été fondé en 1994.
Il est chargé de définir des standards pour les technologies liées aux web telles que HTML ou RDF.
Annexes
Annexe 1 : Description des fonctionnalités de la solution ITM T3 (extraite du site web de Mondeca)
Ø ITM T3 : Gestion de Thésaurus
- interfaces web d'administration des thésaurus permettant un travail distribué et collaboratif
- gestion d'un nombre illimité de thésaurus multilingues avec prise en compte des alphabets latin, cyrillique, arabe, chinois...
- description complète et enrichissable des descripteurs (dénominations multiples, notes d'application, image associée, niveau dans la hiérarchie...)
- gestion des relations de synonymie, terme générique/terme spécifique, terme associé
- gestion de relations métier spécifiques (...est la cause de..., ...est un composant de...)
- gestion des polyhiérarchies
- gestion de relations d'équivalence (mapping) entre thésaurus pour des opérations de transcodification ou rapprochement de contenus hétérogènes
- opérations de fusion des descripteurs
- copie, déplacement de structures hiérarchiques du thésaurus
- édition de liste alphabétique et hiérarchique
- fonctions de recherche, navigation, consultation
- représentation graphique des hiérarchies et des relations de termes associés
- import et export des thésaurus (XML, SKOS) - Accès par API et Services Web
- serveur de terminologie accessible par toutes les applications via des web services
Ø ITM T3 : Dictionnaire de métadonnées
- ITM T3 est par nature un référentiel de métadonnées permettant tout type d'organisation de ce référentiel: listes, thésaurus, taxonomies de classification.
- ITM T3 est utilisé comme référentiel dans les processus d'indexation des contenus. Il peut être appelé par toute application externe pour un contrôle de la validité d'une valeur de métadonnées ou pour obtenir la métadonnée à utiliser.
- ITM T3 permet de gérer des tables d'équivalence entre dictionnaires de métadonnées pour permettre une re-indexation de contenus ou une traduction de requêtes sur des contenus indexés de manière hétérogéne.
- Basé sur les normes URI, RDF, SKOS, ITM permet d'échanger et de publier le dictionnaire de métadonnées dans des formats ouverts
Ø ITM T3 : Un référentiel partagé par tous les outils linguistiques
- Enrichissement des fonctionnalités des outils existants
- moteur de recherche : extension automatisée des recherches sur les synonymes, acronymes, termes plus spécifiques, traduction.
- portail de recherche : utilisation de taxonomies de publication pour la recherche à facette
- text mining : utilisation d'un vocabulaire métier à jour pour piloter l'extraction d'entités nommées
- traduction : utilisation d'un vocabulaire métier multilingue à jour pour les traitements de traduction assistée
- correcteur orthographique : enrichissement du dictionnaire standard avec le dictionnaire métier de l'entreprise
- aide à la compréhension : accès direct à partir d'un clic sur une expression à sa définition dans le référentiel métier.
Annexe 2 : Description des fonctionnalités de la solution Luxid (extraite du site web de Témis)
Ø Luxid® Content Pipeline
· Luxid® Content Pipeline
>> fédère des collections de contenus
>> importe les sources de contenu dans la plateforme Luxid® Content Enrichment pour alimenter le processus d’annotation
· Plusieurs types de connecteurs
>> connexion à des sources structurées de type bases de données scientifiques, techniques ou juridiques, ou fils de presse
>> connexion à des outils de crawling qui naviguent automatiquement sur le web et capturent le contenu des blogs, des twitts, des forums de discussions, des fils RSS, et des pages standard du web
>> connexion à des solutions de gestion de contenu d’entreprise, à des intranets et à des serveurs email
Ø La plateforme Luxid® Content Enrichment
· Luxid® Annotation Factory
>> propose des services d’annotation rapides et fiables
>> réalise des opérations de traitement de corpus comme la catégorisation (la classification de documents dans des catégories prédéfinies) ou le clustering (le regroupement de documents similaires dans des clusters dynamiques)
>> robuste, résistant à la montée en charge et compatible UIMA
>> intègre une interface web d’administration pour centraliser la gestion des paramètres et l’accès aux logs
· Skill Cartridge® Library
>> gamme étendue d’annotateurs spécifiques
>> extrait des entités et des relations ciblées en croisant plusieurs thématiques
· Les outils de productivité de Luxid®
>> ensemble d’outils permettant d’optimiser l’extraction de connaissance réalisée par Luxid® Annotation Factory > plus d'informations
Ø Les outils de recherche, de découverte et de partage de Luxid®
· Luxid® Information Analytics
>> portail web conçu pour rechercher, découvrir et analyser les informations et pour simplifier le partage de la connaissance avec les consommateurs d'information
>> propose des fonctionnalités avancées de recherche d ‘information et d’analyse comme la recherche sémantique, la navigation guidée, la lecture rapide de documents et les analyses multidimensionnelles.
>> fournit des fonctionnalités innovantes de découverte de l’information permettant d’aller plus loin dans la recherche et l’analyse comme par exemple la découverte intuitive fondée sur la similarité, la proximité, ou la mise en relation.
>> propose des fonctionnalités de partage de connaissance innovantes comme ses rapports personnalisables simples à exporter
· LuxidBar™
>> module léger et simple à mettre en œuvre, qui permet d’extraire les informations pertinentes et d’enrichir les contenus à la volée depuis un navigateur internet
>> identifie et localise rapidement les informations pertinentes
>> relie les informations à des contenus externes issues de bases de données payantes, gratuites en open source ou privées et d'intranets d’entreprises
Annexe 3 : Description des fonctionnalités de CONSTELLIO (extrait du site web Constellio)
· Recherche fédérée de toutes les données de l'organisation ;
· Un outil de découverte (recherche par facettes);
· Catégorisation automatique des contenus (avec Carrot 2);
· Moteur de recherche collaboratif (Wiki-capsules);
· Gestion de l'ordre d'apparition des résultats grâce aux liens référencés;
· Apprentissage automatique : gestion de la pertinence avec la consultation des documents et association automatique des mots clés les plus populaires aux documents
· Reconnaissance des noms de personnes, dates, fonctions et autres entités (Apache UIMA);
· Recherche par synonymes;
· Tri des résultats;
· Correcteur orthographique multilingue (basé sur Hunspell, correcteur utilisé par Firefox et OpenOffice);
· Indexation avec des thésaurus (Kea);
· Rapports et statistiques d’indexation et de recherche;
· Détection des liens brisés;
· Support multilingue des interfaces (I18N);
· Support de plus de 15 langues avec lemmatisation de l'indexation;
· Détection automatique de la langue;
· Recherche multilingue;
Bibliographie
Indexation et Recherche d’Information
AMAR, Muriel. « L’indexation aujourd’hui ».
Disponible sur :< http://www2.cndp.fr/archivage/valid/68661/68661-10219-12814.pdf>
BENGHOZI, Pierre-Jean. BERGADAà Michelle. « Métier de chercheur en gestion et Web : risques et questionnements éthiques ». 2012.
Disponible sur : <http://www.esens.unige.ch/documents/metier_de_chercheur_en_gestion_et_web.pdf >
CENTRE de Documentation et d’Information du Lycée Jean Monnel de Montpellier. « Recherche d’information ».
Disponible sur :< http://www.lyc-monnet-montpellier.ac-montpellier.fr/bcdiweb/doc/etapesRI.pdf>
DUBOST, Karl. « RDF et les métadonnées ».
Disponible sur :<http://www.w3.org/2000/Talks/1019-rdf-poly/Overview.html>
Disponible sur :<
EUROSTAT. « Accès et utilisation d’internet en 2011. Dans l’UE27, près d’un quart des personnes de 16 à 74 ans n’ont jamais utilisé internet ». 2011.
Disponible sur :< http://epp.eurostat.ec.europa.eu/cache/ITY_PUBLIC/4-14122011-BP/FR/4-14122011-BP-FR.PDF>
FEYLER, François. Article « Évolution des outils d’indexation documentaire des années 1980 aux années 2010 ». 2011.
HILLMANN, Diane. Traduit par TEASDALE Guy. « Guide d’utilisation du Dublin Core ». 2001.
Disponible sur : <http://www.bibl.ulaval.ca/DublinCore/usageguide-20000716fr.htm#1.1>
Disponible sur :<http://openweb.eu.org/articles/dublin_core>LEISE Fred, FAST Karl et STECKEL Mike.
LEBRETON, Claire. Mémoire d’étude « Bibliothèques, tags et folksonomies. L’indexation des bibliothèques à l’ère sociale ». 2008.
Disponible sur <http://www.enssib.fr/bibliotheque-numerique/document-1750>
LEISE, Fred. FAST, Karl. STECKEL, Mike. Article « Controlled Vocabularies: A Glosso-Thesaurus ». 2003.
Disponible sur: <http://www.boxesandarrows.com/view/controlled_vocabularies_a_glosso_thesaurus>
MENON, Bruno. Article « Les langages documentaires. Un panorama, quelques remarques critiques et un essai de bilan ». Documentaliste, 2007.
Disponible sur <http://www.cairn.info/revue-documentaliste-sciences-de-l-information-2007-1-page-18.htm>
MOREL-PAIR, Catherine. « Panorama : des métadonnées pour les ressources électroniques ». 2005
Disponible sur <http://halshs.archives-ouvertes.fr/docs/00/04/04/73/PDF/Metas_panorama_CMO.pdf>
NIESZKOWSKA, Ewa. Mémoire d’étude « Quelle indexation pour une bibliothèque spécialisée ? Le cas de la bibliothèque de l’Institut français d’architecture ». 2003
Disponible sur <http://enssibal.enssib.fr/bibliotheque/documents/dcb/nieszkowska.pdf>
PIERRE, Béatrice. Mémoire « L’avenir des langages documentaires dans le cadre du Web sémantique : conception d’un thésaurus iconographique pour le Petit Palais ». 2010
Disponible sur <http://memsic.ccsd.cnrs.fr/docs/00/57/50/53/PDF/PIERRE.pdf>
PINCEMIN, Bénédicte. « Thésaurus documentaires et ontologies Divergences et ressemblances ». 2003
Disponible sur :<http://www-ldi.univ-paris13.fr/membres/biblio/1195_pincemin_ws_0410.pdf>
POUPEAU, Gautier. « Perspectives pour les référentiels à l’heure du Web de données ». 2011
Disponible sur :< http://www.slideshare.net/AntidotNet/perspectives-pour-les-rfrentiels-lheure-du-web-de-donnes?src=related_normal&rel=3562847>
RESSAD-BOUIDGHAGHEN, Ourdia. « Accès contextuel à l’information dans un environnement mobile : approche basée sur l’utilisation d’un profil situationnel de l’utilisateur et d’un profil de localisation des requêtes ». 2011.
Disponible sur : <http://thesesups.ups-tlse.fr/1404/1/2011TOU30206.pdf>
RUIZ LEPORES, Domingos. Mémoire d’étude « Des grandes classifications au Web de données et l’émergence de l’indexation sémantique : le cas du tagging sémantique dans le portail Histoire des Arts ». 2011.
Disponible sur : <http://memsic.ccsd.cnrs.fr/docs/00/67/99/06/PDF/RUIZ_LEPORES.pdf >
TADDEI ELMI, Giancario « Synonymie, hyponymie et thésaurus juridiques ». 1981.
Disponible sur <http://promethee.philo.ulg.ac.be/LASLApdf/Actes/78.pdf>
URFIST PARIS. « Nouvelles pratiques d’indexation, nouveaux enjeux documentaires ? »
Disponible sur : <http://urfist.enc.sorbonne.fr/sites/default/files/file/traitementdoc/Pratiques-d%27indexation-support.pdf>
ZACKLAD, Manuel. « Classification, thésaurus, ontologies, folksonomies: comparaisons du point de vue de la recherche ouverte d’information (ROI). »
Disponible sur : <http://www.zacklad.org/articles_soc_web2/presentation%20cais-acsi.pdf>
ZAHER Hédi, CAHIER Jean-Pierre et ZACKLAD Manuel. « Vers la recherche ouverte d’information ».
Disponible sur : http://www.irit.fr/SDC2006/cdrom/contributions/Zaher_et_al_poster_IC06.pdf>
W.NESRINE, Zemirli. « Vers le développement d’un système de recherche d’information personnalisé intégrant le profil utilisateur ». 2003/2004.
Disponible sur : <http://apmd.prism.uvsq.fr/public/Publications/Articles/Vers%20le%20developpement%20d%20un%20systeme%20de%20recherche%20d%20information%20personnalise%20integrant%20le%20profil%20utilisateur_Zemirli.pdf>
Méthodes d’indexation avec ou sans référentiels
ABI CHAHINE. Carlo. Thèse « Indexation et recherche conceptuelles de documents pédagogiques guidées par la structure de Wikipédia ». 2011.
CNDP (Centre national de documentation pédagogique). Guide d’indexation MOTBIS. 2010.
Disponible sur : <http://www.cndp.fr/motbis/telechargement/guide_d_indexation.pdf>
COURSEY, Kino. MIHALCEA, Rada. Etude «Topic Identification Using Wikipedia Graph Centrality ». 2009.
EL HADI WIDAD, Mustafa. « Indexation humaine et indexation automatisée : la place du terme et de son environnement ». 2005.
HUDON, Michèle. Etude « Indexation et langages documentaires dans les milieux archivistiques à l’ère des nouvelles technologies de l’information ». 1997-1998.
LABORIE, Sébastien. CODREANU, Dana. SÈDES, Florence. « Spécification et utilisation d'un modèle de description d'algorithmes d'indexation ». 2010.
LE MAITRE, Jacques. Cours « Recherche d’information ».
MAHMOUDI, Seyed Mohammad. « Indexation automatique et la Recherche d’Information dans les documents ». 2006.
MEDELYAN, Olena. H.WITTEN, Ian. «Topic indexing with Wikipedia ». 2008.
NEVEOL, Aurélie. DARMONI, Stéfan. Chapitre « Recherche d'information, indexation automatique, classification en santé : état de l'art » tiré du l’ouvrage « Terminologie et Accès à l'information ». 2006.
POULIQUEN, Bruno. Thèse « Indexation de textes médicaux par extraction de concepts, et ses utilisations ». 2002.
SAVOY, Jacques. « Indexation manuelle et automatique : une évaluation comparative basée sur un corpus en langue française ». 2005.
Webographie
Delicious : Nous avons répertorié différents liens qui nous ont aidés pour la rédaction de ce rapport.
Disponible sur : <http://www.delicious.com/indexauto>
Indexation et Recherche d’Information
OpenData (Editeur : INSEE). « Statistiques sur l’utilisation et l’accès à internet en France en 2010 ». 2011.
Disponible sur : <http://www.data-publica.com/opendata/4491--statistiques-sur-l-utilisation-et-l-acces-a-internet-en-france-en-2010#>
Wiki de l’université Paris Descartes.
Disponible sur : <http://wiki.univ-paris5.fr/wiki/Indexation>
http://www.larousse.fr/dictionnaires/francais/indexer/42563>
dictionnaire de Guide-Informatique ».
Disponible sur :<http://www.guideinformatique.com/definition-referentiel-710.htm>
Site internet « linternaute.com ». « L’internaute Encyclopédie – Dictionnaire de la langue française »
Disponible sur : <http://www.linternaute.com/dictionnaire/fr/definition/indexer/>
Site internet « Techno-Science.net ». « Folksonomie ».
Disponible sur :<http://www.techno-science.net/?onglet=glossaire&definition=252>
Site internet « Techno-Science.net ». « Recherche d’Information ».
Disponible sur : <http://www.techno-science.net/?onglet=glossaire&definition=11203>
Site internet « tomsguide.fr ». « Le nombre d’internautes a doublerait tous les 5 ans ».
Disponible sur : <http://www.tomsguide.fr/actualite/internautes,3379.html>
Site de l'association des professionnels de l'information et de la documentation (ADBS).
Disponible sur : <http://www.adbs.fr>
Site internet « zdnet.fr ». « 2007-2012 : le nombre d’internautes a doublé dans le monde »
Disponible sur : <http://www.zdnet.fr/actualites/2007-2012-le-nombre-d-internautes-a-double-dans-le-monde-39770934.htm
Méthodes d’indexation avec ou sans référentiels
Site personnel d’Alyona Medelyan.
Disponible sur : <http://www.medelyan.com/software>
Site de la solution Kea++.
Disponible sur : <http://www.nzdl.org/Kea/>
Cours sur le Latent Semantic Indexing.
Disponible sur : http://benhur.teluq.uqam.ca/SPIP/inf6460/article.php3?id_article=120&id_rubrique=8&sem=Semaine%206
Billet de blog sur la lemmatisation et la racinisation.
Disponible sur : http://blog.onyme.com/lemmatisation-et-racinisation-en-francais-flexion-lemme-et-racine-dun-mot/
Wiki de la solution Maui.
Disponible sur : <http://code.google.com/p/maui-indexer/w/list>
Cours sur la Modélisation vectorielle.
Disponible sur : http://benhur.teluq.uqam.ca/SPIP/inf6460/article.php3?id_article=93&id_rubrique=8&sem=Semaine%206
Billet de Blog sur le fonctionnement d’un moteur de recherche.
Disponible sur : http://proxem.wordpress.com/2012/04/04/recherche-semantique-22-comment-fonctionne-un-moteur-de-recherche-non-semantique/
Solutions existantes
Informations sur le nouveau moteur de recherche internet Volunia
Disponible sur :<http://www.presse-citron.net/volunia-vs-google>
<http://actu.abondance.com/2012/02/volunia-premiers-tests-premieres-copies.html>
<http://www.pullseo.com/volunia-moteur-de-recherche-social/>
Statistiques sur l’utilisation des moteurs de recherche internet
Disponible sur :<http://www.comscore.com/fre/>
Evolution de l’algorithme Panda
Disponible sur :< http://www.journaldunet.com/solutions/seo-referencement/seo-mise-a-jour-google-fevrier-2012.shtml?f_id_newsletter=6537>
Solutions Google pour entreprise
Disponible sur :< http://www.google.com/enterprise/search/>
Solutions proposées par Onyme
Disponible sur :< http://www.onyme.com/>
Solutions proposées par Mondeca
Disponible sur :< http://www.mondeca.com/>
Solutions proposées par Témis
Disponible sur :< http://www.temis.com/>
Solutions proposées par Exalead
Disponible sur :< http://www.exalead.com/search/>
Solutions proposées par Ontotext
Disponible sur :< http://www.ontotext.com/>
[1] Une notice documentaire est une fiche qui décrit un document. Elle comporte un ensemble d'indications permettant d'identifier, de localiser et de décrire sommairement le document en question.
[2] Un thésaurus est un ensemble de termes organisés servant à représenter des concepts.
[3] Un référentiel sert de cadre commun. Il rassemble tous les termes et toutes les notions qui doivent être échangés.
[4] Une métadonnée est une donnée qui décrit une autre donnée.
[5] Source : college-petite-camargue.net
[6] Source :http://www.mediametrie.fr/internet/communiques/la-frequentation-des-sites-internet-francais-en-avril-2012.php?id=651
[7] Source :http://www.zdnet.fr/actualites/2007-2012-le-nombre-d-internautes-a-double-dans-le-monde-39770934.htm et http://www.tomsguide.fr/actualite/internautes,3379.html
[8] Source :http://www.data-publica.com/opendata/4491--statistiques-sur-l-utilisation-et-l-acces-a-internet-en-france-en-2010# (année 2010)
[9]http://apmd.prism.uvsq.fr/public/Publications/Articles/Vers%20le%20developpement%20d%20un%20systeme%20de%20recherche%20d%20information%20personnalise%20integrant%20le%20profil%20utilisateur_Zemirli.pdf(p12 sur 73)
[11] GNU General Public License (communément abrégé GNU GPL) est une licence qui fixe les conditions légales de distribution des logiciels libres du système d’exploitation GNU.
[12] Jena est un framework open-source programmé en Java permettant de construire des applications du web sémantique. Il permet notamment de traiter des documents au format SKOS, RDF, OWL…
[13] GNU General Public License (communément abrégé GNU GPL) est une licence qui fixe les conditions légales de distribution des logiciels libres du système d’exploitation GNU.
[14] Wikipedia Miner (http://wikipedia-miner.cms.waikato.ac.nz/index.html) est un outil permettant d’intégrer le contenu de Wikipédia à une application. Il place le contenu dans une base de données MySQL et donne la possibilité à l’application d’accéder à des parties du contenu de Wikipédia (comme des titres de pages…)
[16] « La similarité cosinus (ou mesure cosinus) permet de calculer la similarité entre deux vecteurs à dimensions en déterminant l'angle entre eux. Cette métrique est fréquemment utilisée en fouille de textes. » Source : http://fr.wikipedia.org/wiki/Similarit%C3%A9_cosinus
[17] La Bibliothèque du Congrès assure la fonction de bibliothèque de recherches du Congrès des États-Unis. Elle se situe à Washington aux Etats-Unis. C'est la bibliothèque la plus importante du monde en nombre de livres. Cette bibliothèque est la mieux équipée au monde en systèmes informatiques.
[18] Karl Dubost a été Web Community Liaison, HTML WG staff contact, QA Activity Lead et Conformance Manager pour le W3C. Il travaille maintenant comme Web Opener pour Opera Software. http://www.la-grange.net/2004/03/19.html
[19] RUIZ LEPORES, Domingos. Mémoire d’étude « Des grandes classifications au Web de données et l’émergence de l’indexation sémantique : le cas du tagging sémantique dans le portail Histoire des Arts ». 2011.
http://memsic.ccsd.cnrs.fr/docs/00/67/99/06/PDF/RUIZ_LEPORES.pdf
[20] http://dossierdoc.typepad.com/descripteurs/2005/08/le_web_smantiqu.html
[21] Site internet « guideinformatique.com ». « Le dictionnaire de Guide-Informatique ».
Disponible sur :<http://www.guideinformatique.com/definition-referentiel-710.htm>
[22] OWL (Ontologic Web Language) est un langage basé sur RDF qui définit un vocabulaire riche pour la description d'ontologies complexes. Ce langage est basé sur une sémantique formelle définie par une syntaxe rigoureuse.