Web sémantique
sur les systèmes embarqués
Sommaire
2.2.1. La tour du Web Sémantique : Vision du W3C
2.2.3. Syntaxe : XML (Extensible Markup Language)
2.2.4. Technologies standards du web sémantique
2.2.5. Technologies non réalisées
2.2.6. Technologies alternatives
2.4.1. E-commerce (BestBuy.com)
2.4.3. Web personnalisé (Cruzar)
2. Le web sémantique
2.1. Présentation et contexte
2.1.1. Le Web
En 1989, Tim Berners-Lee, travaillant au CERN (Conseil européen pour la Recherche nucléaire) invente le Web (World Wide Web) en liant le principe d’hypertexte avec Internet. Surfer sur le net, partager des documents, échanger avec des millions de personnes à travers le monde… Tout ceci n’aurait pas été possible sans l’invention du World Wilde Web. Le Web a été pendant les premières années de son apparition un outil de diffusion, où un ensemble de producteurs de contenu diffusent l’information aux internautes, via des pages HTML simples liées entre elles par des hyperliens. C’est ce qu’on appelle le Web 1.0 auquel succédé le Web 2.0.
Outre les évolutions techniques, le Web 2.0 se traduit par une évolution des usages. Grâce aux interfaces simplifiées, l’internaute s’approprie plus facilement le contenu du Web et ses nouvelles fonctionnalités. Avec les nouvelles applications (blogs, wikis, réseaux sociaux), les utilisateurs peuvent participer à la création du contenu. Le Web 2.0 est marqué par l’interactivité entre les utilisateurs, l’échange et le partage d’informations, c’est ce qu’on appelle le Web social. Mais le Web ne cesse d’évoluer. De nos jours, la question qui se pose, c’est quel serait le web de demain?
L’évolution future du Web 2.0 est souvent désignée par le terme Web 3.0. Deux évolutions majeures sont pressenties. Certains spécialistes voient le Web sémantique comme la future évolution du Web, d’autres pensent que le Web 3.0 sera l’internet des objets[i]. Cependant, le Web 3.0 pourrait être la conjonction des deux thèses précédentes. Dans l’internet des objets, les objets physiques sont identifiés de manière unique, avec des codes-barres, des étiquettes RFID…etc. les données sur les comportements de ces objets sont collectées via des dispositifs tels que les capteurs. Ainsi, le Web sémantique permettrait de structurer et de mieux exploiter les données collectées.
2.1.2. Le Web Sémantique
Le Web sémantique, est un ensemble de technologies dont le but est d’offrir une structure commune aux données présentes sur le web. Les documents non structurés sont ainsi convertis en web de données, mais il n’existe aucun outil permettant de convertir automatiquement les documents sans une intervention humaine. . Un sens compréhensible à la fois par l’Homme et la Machine peut être associé aux données et aux relations entre elles. Les données seront alors exploitables directement par les machines et pourront être traitées sans intervention humaine. Ainsi, l’objectif du Web sémantique est non seulement de constituer un réseau global de données structurées, mais aussi de faire en sorte que l’information soit compréhensible par des machines et des agents logiciels.
Dans le magazine, Scientific American, le Web sémantique a été défini par Tim Berners-Lee, James Hendler et Ora Lassila comme une extension du Web actuel (Web 1.0 à l’époque) où on donne à l’information une sémantique, un sens bien défini, qui permettrait aux ordinateurs et aux personnes de travailler en collaboration.
"The Semantic Web is an extension of the current web in which information is given well-defined meaning, better enabling computers and people to work in cooperation[ii]."
L’ensemble des technologies en rapport avec le web sémantique est représenté dans ce qu’on appelle le « Web sémantique tower » (cf. 2.2.Technologies).
Les technologies du Web sémantique peuvent être utilisées dans de nombreux domaines d’applications (ceci est une liste non exhaustive):
· Dans l’intégration de données, où des données de provenance (serveurs) et de format variés peuvent facilement être intégrées à une application.
· Dans la recherche et la classification des ressources afin de fournir aux moteurs de recherche la capacité d’effectuer des recherches plus précises (ex : Quelle est la capitale de France ?).
· Dans le catalogage, afin de décrire le contenu et ses relations avec d’autres contenus.
· Dans les agents logiciels intelligents afin de faciliter le partage de leurs connaissances.
· Dans l’évaluation du contenu.
· Dans la description de collections de pages représentant un seul document logique.
2.1.3. Contexte
À l'origine, dans sa vision du Web sémantique, Tim Berners Lee avait imaginé un agent qui pourrait confirmer ou infirmer une théorie scientifique.
En effet, l'objectif du Web sémantique est de pouvoir créer des agents sur le réseau (logiciels, robots...) qui sont en mesure d'interpréter l'information disponible. L'une des problématiques qui se posent est la communication entre machines. Le but est de faire en sorte que deux machines puissent communiquer entre elles sans intervention humaine. En effet le Web sémantique permet de décrire les informations du Web de manière à ce qu’elles soient compréhensibles pour les machines.
2.2. Technologies
2.2.1. La tour du Web Sémantique : Vision du W3C
L’ensemble des technologies du Web sémantique est organisé dans une architecture en couches. C’est ce qu’on appelle la « Semantic Web Stack » ou « Pile du Web Sémantique » (voir figure 1). Elle constitue la vision du W3C de l’architecture du Web Sémantique. Ainsi l’ensemble des technologies (langages et protocoles) qu’elle comporte, sont standardisées par le W3C, et font toujours l’objet de recherches et de travaux d’amélioration et de normalisation au sein du W3C.
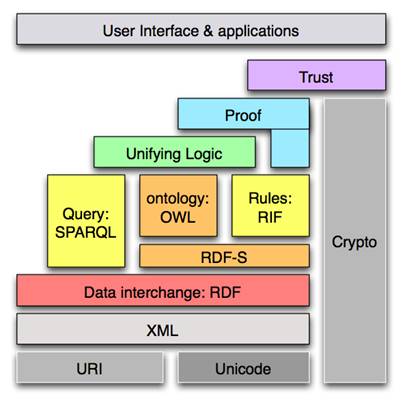
Figure 2 - Pile du Web sémantique (Semantic Web Stack)
Certaines couches sont déjà implémentées. En effet, les langages et protocoles qui permettent de remplir leurs fonctions existaient déjà ou ont été conçus et créés pour répondre aux spécifications de chaque couche. Le Web sémantique est encore un grand chantier, les couches supérieures ne sont pas encore très évoluées, mais le rôle qu’elles doivent occuper est globalement défini.
Chaque couche utilise la couche du dessous, et a une fonction bien déterminée dans l’architecture.
Nous allons voir les fonctions de chaque couche ainsi que les langages et/ou protocoles qui leur sont liés.
2.2.2. Technologies HTTP
· Les identifiants : Les URI (Uniform Resource Identifiers)
Cette couche est utilisée pour l’identification de chaque ressource sur le réseau. Elle utilise les URIs, des chaines de caractères permettant d'identifier une ressource quelconque de manière permanente.
RDF utilise les URIs afin d'identifier chacune de ces entités, d’où le lien avec les couches supérieures.
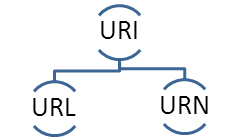
· Les URL (Uniform Resource Locator)
Outre la représentation unique d’une ressource, les URI de ce type impliquent une représentation de la ressource. À titre d’exemple, une page Web est une ressource identifiée par une URL. Cette même URL est associée à une représentation de cette même ressource. Pour notre exemple, le document HTML qui décrit la page Web constitue une représentation de la ressource (la page Web) identifiée par une URL.
· Les URN (Uniforme Resource Name)
Une ressource est identifiée par son nom par rapport à un espace de nommage. Les noms à l’intérieur d’un espace de nommage sont uniques, afin d’éviter toute ambiguïté entre les éléments ayant des noms identiques. Elle permet de nommer une ressource sans forcément qu’elle soit accessible via le Web.
2.2.3. Syntaxe : XML (Extensible Markup Language)
XML correspond à la couche Syntaxe. Il donne la syntaxe pour décrire la structure du document, il permet de définir des espaces de nommages qui peuvent avoir un vocabulaire, mais n’inclut pas une dimension sémantique, d’où l’utilisation de RDF.
2.2.4. Technologies standards du web sémantique
Data
interchange: RDF (Resource Definition Framework)
C'est un langage permettant de décrire des ressources web grâce à des
triplets de la forme : (Sujet, prédicat, objet).
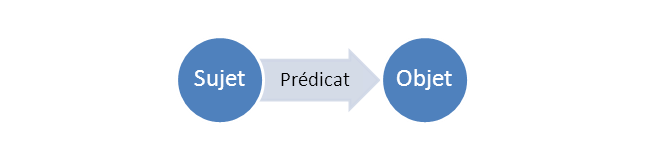
C’est un modèle standard pour l'échange de données sur le « Web of Objets ». Il facilite la fusion des données même si les schémas sous-jacents diffèrent.
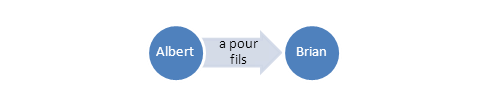 |
On voudra par exemple représenter l’idée « Albert a un fils nommé Brian »
En RDF/XML on écrira :
<rdf:Description about="#albert"
<family:child rdf:Resource="#brian">
</rdf:Description>
Le W3C propose également une intégration directe des triplets dans le langage HTML avec à la norme RDFa:
<p about="#albert" >
<span property="family:child">Brian</span> est le fils d’Albert
</p>
Il existe aussi d’autres notations moins utilisées telles que la notation N3 :
<#albert> family:child <#brian>
Taxonomies: RDFs (RDF schema)
RDF Schéma est une extension de RDF. Il correspond à la couche taxonomie[1]. C’est un métavocabulaire, c’est-à-dire un vocabulaire qui permet d’en décrire d’autres. En effet, dans le web sémantique « un vocabulaire (ou "vocabulaire contrôlé") »[2].
Ontologies : OWL (Web Ontology Langage)
Une ontologie désigne une modélisation ainsi que la structure qu’elle modélise. Si on prenait comme exemple un texte, on s’intéresse autant à la structure qu’au sens. Cette couche utilise le langage OWL, qui est basé sur RDF. C’est une extension de RDF Schémas. Il définit un vocabulaire riche pour décrire les ontologies.
Une des ontologies les plus utilisées est le projet FOAF (Friend Of A Friend) qui permet de décrire des personnes et les relations qu’elles entretiennent entre elles.
Un exemple concret consisterait par exemple à décrire Mr Dan Brickley, avec son adresse mail, son site web ainsi qu’une de ses connaissances :
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">
<foaf:Person>
<foaf:name>Dan Brickley</foaf:name>
<foaf:title>Mr.</foaf:title>
<foaf:givenName>Dan</foaf:givenName>
<foaf:familyName>Brickley</foaf:familyName>
<foaf:mbox rdf:resource="mailto:webmaster@foaf-project.org"/>
<foaf:homepage rdf:resource=" http://danbri.org/"/>
<foaf:knows>
<foaf:Person">
<foaf:name> Libby Miller</foaf:name>
</foaf:Person>
</foaf:knows>
</foaf:Person>
</rdf:RDF>
Quering: SPARQL (SPARQL Protocol and RDF Query Language)
Comme son nom l'indique, SPARQL est un protocole et un langage qui permet de faire des requêtes sur les données RDF. SPARQL est l’équivalent de SQL pour le Web des données. L’un des avantages de SPARQL est le fait qu’il se base directement sur les métadonnées RDF. Cela permet aux machines ou aux humains d’interroger des bases de données sur le Web, sans forcément en connaitre le schéma au préalable, ce qui permettrait un accès aux données sans intermédiaire.
Source (décembre 2011) : Recommandation de SPARQL : http://www.w3.org/TR/rdf-sparql-query/
Rules : SWRL et RIF
Il existe différents langages de règles, cette couche a pour objectif de normaliser la représentation des règles RDF. Elle comporte deux langages de règles : SWRL (Semantic Web Rule Langage) et RIF (Rule Interchange Format). SWRL est une extension de OWL qui normalise la représentation des règles au format RDF. RIF ne repose pas directement sur RDF mais sur XML et il permet plutôt de faciliter l’utilisation et l’échange de règles entre les formats déjà existants.
Source (décembre 2011) :
Recommandation de RIF (06-2010) : http://www.w3.org/TR/rif-bld/
Utilisation de RIF en combinaison avec RDF et OWL: http://www.w3.org/TR/rif-rdf-owl/
Soumission de SWRL : http://www.w3.org/Submission/SWRL/
2.2.5. Technologies non réalisées
Les couches supérieures de la pile du Web sémantique contiennent des technologies qui ne sont pas encore standardisées ou contiennent seulement des idées qui devraient être mises en œuvre afin de réaliser le Web sémantique.
Les couches Logic, Proof et Trust :
Ces trois couches n’ont pas encore été implémentées. Elles s’appuieront les unes sur les autres afin de permettre l’identification et la validation des informations récoltées grâce aux données RDF.
La couche Logic est la première de ces couches. Son nom est assez transparent : elle donne la possibilité de construire des moteurs d’inférence logique afin de faire des liens entre les entités RDF sans que ceux-ci soient explicitement exprimés. Elle se baserait pour ça sur les règles définies par la couche Rules. La couche Logic sera à la couche Rules ce que la couche OWL est à la couche RDF c’est-à-dire qu’on cherche à regrouper les règles pour leurs donner un sens et les rendre utilisable.
La couche Proof utilisera la couche logique afin d’assurer la vérification des déclarations effectuées dans le Web sémantique.
Enfin la couche Trust vient s’appuyer sur les deux autres et c’est elle qui permettra de contrôler la véracité d’une information en attribuant plus ou moins de confiance aux sources de données rencontrées lors de la recherche
Source (décembre 2011) :
Introduction au RDF : http://infomesh.net/2001/swintro/#trustAndProof
Réflexion sur les couches Proof et Trust : http://www.seoskeptic.com/open-linked-data-discovery-proof-and-trust/
La couche Cryptography
Cette couche a pour but de s’assurer et de vérifier que les déclarations issues du Web sémantique proviennent d’une source sure, ce qui peut être réalisé par la signature numérique[3] des déclarations RDF.
User interface
C’est ici la dernière couche permettant à l’homme d’utiliser des applications en web sémantique. Elle n’est pas spécialement placée au sommet, mais plutôt au-dessus de la dernière couche développée et elle évolue en même temps que le reste des technologies.
2.2.6. Technologies alternatives
Microdatas (Microdonnées)
Ce sont des attributs introduits avec HTML5 et permettant d'inclure du contenu sémantique, c'est-à-dire des métadonnées, directement dans une page web. Les microdatas ont été créées dans le but de simplifier la manière d’annoter les éléments HTML avec une approche similaire au RDFa.
Le W3C a lancé le groupe « HTML Data Task Force » qui pour but de faciliter la transformation de données décrites en utilisant les microdatas en RDFa et inversement.
Microformats
C’est une alternative aux ontologies basée sur l'utilisation des microdatas qui ont la même finalité, mais qui ne sont pas développés par le W3C.
En effet, les microformats sont un ensemble de conventions qui, incorporées à une page HTML, permettent de mieux en exploiter le contenu. À titre d’exemple, les tags ainsi que les personnes ayant laissé des commentaires sur des sites comme You Tube sont décrits avec les microformats.
Exemple d’une , il y a le format hcard qui permet de représenter des personnes et des organisations :
<div class="vcard">
<a class="url fn org » href="http://www.xebia.fr/">Xebia</a>
<a class="email » href="mailto:info@xebia.fr">info@xebia.fr</a>
<div class="adr">
<div class="street-address">10/12 Avenue de L'Arche</div>
<span class="locality">Courbevoie</span>,
<span class="postal-code">92 419</span>
<span class="country-name">France</span>
</div>
<div class="tel">
<span class="type">Work</span>+33 (0)1 53 89 99 99
</div>
<div class="tel">
<span class="type">Fax</span>+33 (0)1 53 89 99 97
</div>
<a rel="me » class="url » href="http://fr.twitter.com/#!/XebiaFr">Twitter</a>
<a rel="me » class="url » href="https://github.com/xebia-france">Github</a>
</div>
Cet exemple décrit une organisation « Xebia » ayant un site et une adresse email. Elle possède également une adresse géographique (classe « adr ») et deux numéros de téléphone (fixe/fax). Deux autres profils sont consultables en ligne (Twitter et Github).
Le W3C propose un standard permettant de faciliter la conversion des microformats en RDF : le GRDDL (Gleaning Resource Descriptions from Dialects of Languages)
Schema.org
Schema.org propose les « schémas », des modèles de données génériques dérivé de RDFS mais basé directement sur les microdatas plutôt que sur la norme RDF. Le concept de ces schémas se rapproche fortement des ontologies de la pile du W3C. Les créateurs de Schema.org ont décidé de favoriser les microdatas au RDFa, car ils considéraient la norme du W3C trop lourde et trop complexe à mettre en place pour les webmasters.
Schema.org a acquis un poids considérable durant l’été 2011, lorsque les 3 principaux moteurs de recherche ont décidé d’un commun accord de soutenir ce site et ses acteurs.
2.3. Acteurs impliques
|
Groupes de travail |
|
|
W3C |
Le W3C est un organisme de standardisation. Il est chargé de promouvoir la compatibilité des technologies du Web. Le W3C est l’initiateur de nombreux groupes de travail qui œuvre à l’amélioration des normes déjà existante ainsi qu’à la conception des normes futures. |
|
Schema.org |
Groupe créé pour proposer une alternative à la norme du W3C sur le web sémantique, car celle-ci était jugée trop complexe. Ils ont depuis obtenu le soutien des trois principaux moteurs de recherche qui utilise désormais les schémas proposés dans leur indexation |
|
Les moteurs de recherches Les moteurs de recherche sémantique sont l'avenir de la recherche sur le web pour fournir aux utilisateurs des réponses non plus basées sur des mots clés, mais directement sur le contenu en exploitant les métadonnées. Ils auront donc un rôle prépondérant dans le futur du web sémantique et l’orientation des recherches dans ce domaine. |
|
|
|
Google a fait l’acquisition de Metaweb en 2010 afin de développer sa branche sémantique et d’améliorer son moteur de recherche. |
|
Bing |
Microsoft rachète Powerset en 2008 (un moteur de recherche en langage naturel) pour pouvoir intégrer la recherche sémantique à son nouveau moteur. |
|
Yahoo! |
Le moteur de recherche de Yahoo! prend en charge les technologies du web sémantique, les microformats et Schema.org. Yahoo! a lancé en 2011 le Semantic Search Challenge, une compétition basée sur la recherche sémantique et dont les résultats ont pu servir de base de discussion à des groupes de travail lors de la conférence WWW2011. |
|
Siri (Apple) |
Siri qui es un assistant personnel intelligent, utilise la sémantique des données du web afin de répondre aux requêtes des utilisateurs. |
|
Wolfram Alpha |
Wolfram Alpha est un moteur de recherche sémantique lancée en 2009. |
2.4. Applications
Nous présenterons une application du web sémantique pour les principaux domaines d’utilisation. La recherche de ces applications a été effectuée avant la veille.
2.4.1. E-commerce (BestBuy.com)
BestBuy.com utilise le web sémantique afin d’être mieux référencé par les moteurs de recherche. En effet, Google par exemple, utilise les métadonnées du web sémantique que contiennent les sites internet afin de répondre à une requête complexe comme « Où acheter une télévision Samsung ? »[4].
L’objectif principal de l’utilisation des technologies sémantiques est d’accroître la visibilité de ses produits et services. En utilisant des données telles que le nom du magasin, l'adresse, heures d'ouverture et des données de GEO ont été balisé à l'aide de RDFa. Les moteurs de recherche sont capables d'identifier chacun de ces éléments de données facilement et de les mettre en contexte. Best Buy a créé pour chaque magasin son propre blog.
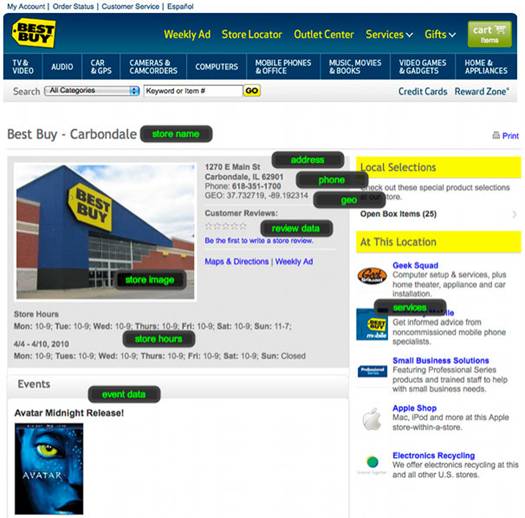
Figure 3 - Une page de description d’un magasin
Les employés de Best Buy entrent chaque jour les informations dans les blogs en utilisant les formulaires de productivité en ligne de RDFa. Les technologies du web sémantique sont aussi utilisées pour décrire les produits vendus.
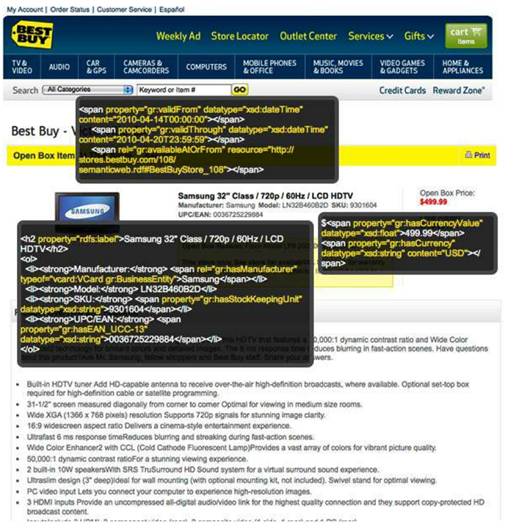
Figure 4 - Une page de description d’un produit
Nous pouvons constater l’utilisation du vocabulaire de l’e-commerce « GoodRelations » par exemple avec les lignes :
$<span poperty= « gr :hasCurrencyValue »
datatype= »xsd :float »> 499.99</span>
<span property=”gr:hasCurrency” datatype=”xsd:string”
content=”USD”></span>
La première ligne indique que la valeur est de 499.99. La deuxième ligne indique que la devise est le dollar américain.
L’augmentation du trafic de recherche a ainsi augmenté de 30%. De plus, le RDFa peut créer des relations riches entre les produits, qui vont à leur tour "créer une meilleure visibilité à de nouveaux produits" quand un client fait du shopping.
Beaucoup de sites marchands ont intérêt à suivre son exemple.
Source (décembre 2011) : http://www.readwriteweb.com/archives/how_best_buy_is_using_the_semantic_web.php
2.4.2. Recherche (DBpedia)
DBpedia est un projet d'extraction de données de Wikipédia pour en proposer une version web sémantique structurée. Ce projet est mené par l'Université de Leipzig, l'Université libre de Berlin et l'entreprise OpenLink Software.
DBpedia utilise sa propre ontologie contenant 320 classes formant une hiérarchie et qui sont décrites par 1650 propriétés différentes[5].
Il est possible d’interroger la base de données avec l’utilisation de SPARQL. Les données de DBpedia sont liées avec d’autres jeux de données, par exemple pour la page de la Corée du Sud. DBpedia propose un lien (owl :sameAs) vers le jeu de données du New York Times[6].
2.4.3. Web personnalisé (Cruzar)
Cruzar est une application web utilisant des règles et des ontologies et un entrepôt de données afin de construire un itinéraire personnalisé pour chaque profil de visiteur. Cette application a été créée pour la ville de Saragosse, une grande ville touristique d’Espagne.
Les données contenues dans les bases de données sont transformées en données RDF en utilisant des adaptateurs spécifiques.
Une ontologie (voir Figure 5) est utilisée pour organiser les données RDF. L’ontologie de Cruzar prend les informations sur 3 types de domaines:
· Les ressources du tourisme de Zaragoza, événements principaux et points d’intérêt
· Les profiles des utilisateurs pour récupérer les préférences des visiteurs et leurs contextes
· La configuration du parcours
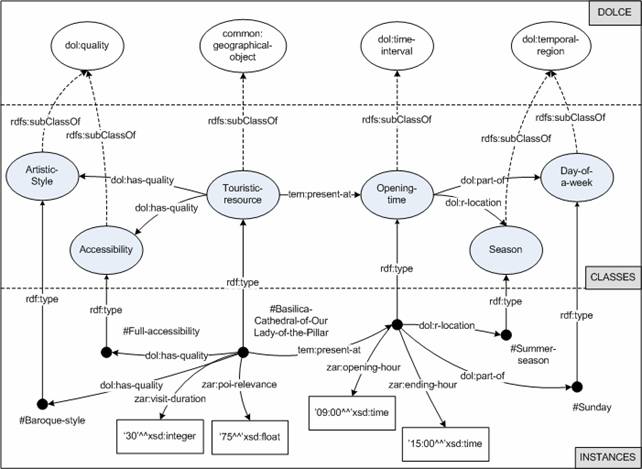
Figure 5: Ce diagramme montre comment l’ontologie décrit les ressources de Saragosse
Les événements et points d’intérêt sont définis avec leurs caractéristiques intrinsèques : position, style artistique ou date. De même les profiles des visiteurs contiennent des informations sur leurs préférences et leurs voyages : date d’arrivé, composition du groupe, activités préférées, etc.
Dans le but de faire correspondre les informations locales avec les informations des préférences, un vocabulaire partagé est nécessaire. Le concept central de ce vocabulaire intermédiaire est « l’intérêt ». Les préférences des visiteurs sont traduites en une collection d’ « intérêts ». Les points d’intérêts et événements de Saragosse peuvent être attrayants pour certaines personnes, cela dépend de leurs « intérêts ». La traduction des informations en « intérêts » se fait via la production de règles, qui sont exécutées par le moteur de règles Jena. Enfin un algorithme planificateur est exécuté afin de créer un parcours personnalisé.
Source (décembre 2011) : http://www.w3.org/2001/sw/sweo/public/UseCases/Zaragoza-2/