Les transactions ETL
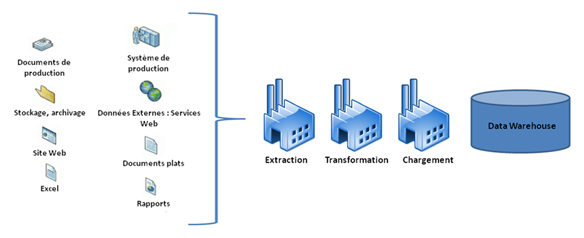
Un ETL, acronyme d’Extraction-Transformation-Loading est un système de chargement de données depuis les différentes sources de l’entreprise jusqu’à l’entrepôt de données. Afin de charger correctement ces données, ce système s’occupe de réaliser différentes opérations.
-
EXTRAIRE : Accéder à la majorité des systèmes de stockage de données (SGBD, ERP, fichiers à plat…) afin de récupérer les données identifiées et sélectionnées.
-
TRANSFORMER : Toutes les données ne sont pas utilisable telles qu’elles. Elles doivent être vérifiées, reformatées, nettoyées et enfin consolidées.
-
CHARGER : Insérer les données dans le datawarehouse. Elles sont ensuite disponibles pour les différents outils d’analyse et de présentation comme les tableaux de bord, l’analyse multidimensionnelle OLAP, le Data Mining, les requêteurs et autres reportings.
Les termes Back Room (la cuisine) ou Data Staging Area sont souvent utilisés par l’industrie pour décrire les systèmes ETL.
Les processus ETL sont les composants les plus critiques et les plus importants d’une infrastructure décisionnelle. Bien que cachés de l’utilisateur de la plate-forme décisionnelle, les processus ETL rassemblent les données à partir des systèmes opérationnels et les prétraitent pour les outils d’analyse et de reporting. La précision et la vitesse de la plate-forme décisionnelle toute entière dépendent des processus ETL. D’ailleurs Ralph Kimball, un informaticien et chef d'entreprise américain, après dix huit mois d’études des ETL, en a définit 38 sous-systèmes et il a statué que 70% d’un projet d’entrepôt de données est dédié aux systèmes ETL.
Aujourd’hui, l’Open Source a pris une part importante du marché et beaucoup d’ETL se fondent au sein d'offres plus globales d'intégration de données.
Synthèse des solutions à suivre :
| Editeur | Solution | Tarif | Références |
|---|---|---|---|
| IBM | Datastage Server Datastage PX |
Dès 21.000€ | NC. |
| Talend | Open Studio | Gratuit | Groupe Accor, GMF, Direction Générale de la Comptabilité Publique... |
| Pentaho | Data Integration | Dès 2.000€ | T Mobile, Ericsson, General Electric... |
| Informatica | Power Center | Dès 50.000€ | Verizon Business, Société Générale, Sanofi Aventis... |
Autres offres du marché :
| Editeur | Solution | Commentaire |
|---|---|---|
| Microsoft | SQL Server 2008 | |
| Oracle | Oracle Warehouse Builder | |
| Cognos | Data Manager | |
| Clover.ETL | Clover.ETL | En gérant les processus légers (threads) de façon indépendante, Clover.ETL partage la charge de transformation sur différents processeurs et s'adapte ainsi aux multiples configurations matérielles. |
| SAS | Data Integration Server | L'éditeur propose sa solution en mode intégré ou bien en SaaS et dispose notamment de connecteurs natifs pour les ERP SAP, PeopleSoft, Oracle et Siebel. |
| SAP Business object | Data Integrator | Fonctionnalité de centralisation des metadonnées et module complet de qualité des données (normalisation, correction...). |
| iWay Software | iWay DataMigrator | DataMigrator s'interfaçe avec les principaux SGBDR du marché en utilisant une palette de connecteurs. |
Manapps, une équipe d'experts spécialisés dans les Nouvelles Technologies, le CRM, le MDM et la BI a publié une mise à jour d’un benchmark très contestée sur les performances de 5 ETL. Fin 2008, une première volée de tests avait clairement placé l’ETL Open Source édité par Talend en tête devant les ETL d’IBM, de Pentaho et d’Informatica. Le leader mondial de l’ETL se voyait assassiné dans les tests, ce qui allait déclencher un torrent de réactions sur le Web.
La nouvelle étude évalue les performances d’IBM Datastage Server 7.5, de Datastage PX 7.5, de Talend Open Studio 2.4.1, d’Informatica 8.1.1 et de Pentaho Data Integrator 3.0.0. Le benchmark porte sur 11 tests différents, de complexité croissante avec des volumétries de données identiques au premier test et avec un simple PC de bureau sous xp comme machine de test. Cette fois, c’est Informatica qui s’en tire le mieux. L’américain obtient la meilleure note globale, devant Talend, les deux ETL IBM (Datastage PX devance Datastage server) et enfin Pentaho qui clôt le classement. Le benchmark est disponible gratuitement sur le site du cabinet de consulting.
L’implémentation de processus d’ETL efficaces et fiables comprend de nombreux challenges.
-
Les volumes de données sont en croissance exponentielle et les processus d’ETL doivent traiter des quantités importantes de données. Certains systèmes décisionnels sont mis à jour de façon incrémentale, alors que d’autres sont rechargés dans leur totalité à chaque itération.
-
Alors que les systèmes d’information se complexifient, la variété des sources de données s’accroît également. Les processus d’ETL doivent disposer d’une large palette de connecteurs à des progiciels (ERP, CRM, etc...), bases de données, mainframes, fichiers, Services Web...
-
Toutes les structures et applications décisionnelles (datawarehouse, datamart, applications OLAP...) présentent des besoins différents en termes de transformation de données, ainsi que des latences différentes.
-
Les transformations des processus d’ETL peuvent être très complexes, et certaines, spécifiques au décisionnel, sont aussi requises.
-
Le décisionnel se rapproche du temps réel, les datawarehouses et datamarts doivent donc être rafraîchis plus souvent sachant qu’il faut éviter les fenêtres de chargement.
Concernant l’avenir de l’ETL, il se situe peut être dans le cloud. En effet, Informatica s’est positionné sur cette niche de marché en proposant Informatica on-Demand. Nicholas Goodman, consultant et fondateur de Bayon Technologies s’est livré à un benchmark de la plate-forme Penthano Data Integration déployée sur Amazon EC2. L’argument de ce choix est financier et il est de taille : 4$ facturés pour l’utilisation de 40 serveurs de petite taille (1 coeur + 1,7Go de RAM) et 2,80$ pour les 20 To d’espace de stockage. C’est dans ce mode de facturation d’Amazon EC2 que se cache l’intérêt du cloud pour l’ETL. Il n’est pas plus coûteux de louer 100 machines pour un temps t qu’une machine durant 100 fois ce temps. Pour peu que la montée en charge de l’ETL soit proche du linéaire, on va pouvoir mobiliser pour un traitement ETL un nombre de machines qu’il serait totalement inenvisageable d’avoir dans son propre datacenter. On assiste à un véritable changement de modèle qui pourrait très vite se développer dans un avenir proche.
Accès directs





 |
 |