Video annotations are a way to get videos to the hypermedia realm. We have designed various models and systems for manual video annotation, as well as video annotation consumption.
-

ACAV: Collaborative Annotation for Video Accessibility
Accessibility
Document Engineering
Video Annotations
ACAV was dedicated to improving web video accessibility through annotations, mainly aimed at hard-hearing, deaf and blind people. We proposed a modeled approach to video enrichment, and studied various renderings with blind subjects.
Details
Partners: LIRIS, EURECOM, Dailymotion
Funding: French Industry Ministry funding, "Innovative web"
Beginning: 2009-10-01
End: 2011-10-30
Related publications
-
Benoît Encelle, Magali Ollagnier-Beldame, Yannick Prié. (2013) Towards the usage of pauses in audio-described videos in W4A 10th International Cross-Disciplinary Conference on Web Accessibility, may 2013. doi Show abstract Classical audiodescription process for improving video accessibility sometimes finds its limits. Depending on the video, required descriptions can be omitted because these may not fit in the durations of "gaps" in the video soundtrack (i.e. "void" spaces between dialogues or important sound elements). To address this issue, we present an exploratory work that focuses on the usage of "artificial" pauses in audio-described videos. Such pauses occur during the playing of the video so as to transmit more audio-descriptions. Our results show artificial pauses offer a good acceptability level as well as a low disturbing effect.
-
Benoît Encelle, Magali Ollagnier-Beldame, Stéphanie Pouchot, Yannick Prié. (2011) Annotation-based video enrichment for blind people: A pilot study on the use of earcons and speech synthesis in 13th International ACM SIGACCESS Conference on Computers and Accessibility. Dundee, Scotland. pp. 123-130. Oct 2011. doi Show abstract Our approach to address the question of online video accessibility for people with sensory disabilities is based on video annotations that are rendered as video enrichments during the playing of the video. We present an exploratory work that focuses on video accessibility for blind people with audio enrichments composed of speech synthesis and earcons (i.e. nonverbal audio messages). Our main results are that earcons can be used together with speech synthesis to enhance understanding of videos; that earcons should be accompanied with explanations; and that a potential side effect of earcons is related to video rhythm perception.
-
J.F. Saray Villamizar, B. Encelle, Y. Prié, P-A. Champin. (2011) An Adaptive Videos Enrichment System Based On Decision Trees For People With Sensory Disabilities in 8th International Cross-Disciplinary Conference on Web Accessibility, Hyderabad, India Show abstract The ACAV project aims to improve videos accessibility on the Web for people with sensory disabilities. For this purpose, additional descriptions of key visual/audio information of the video, that cannot be perceived, are presented using accessible output modalities. However, personalization mechanisms are necessary to adapt these descriptions and their presentations according to user interests and cognitive/physical capabilities. In this article, we introduce the concepts needed for personalization and an adaptive personalization mechanism of descriptions and associated presentations is proposed and evaluated.
-
Pierre-Antoine Champin, Benoît Encelle, N.W.D. Evans, Magali Ollagnier-Beldame, Yannick Prié, Raphaël Troncy. (2010) Towards Collaborative Annotation for Video Accessibility in 7th International Cross-Disciplinary Conference on Web Accessibility (W4A 2010), Raleigh, USA. 2010. doi Show abstract The ACAV project aims to explore how the accessibility of web videos can be improved by providing rich descriptions of video content in order to personalize the rendering of the content according to user disabilities. We present a motivating scenario, the results of a preliminary study as well as the different technologies that will be developed.
-
Benoît Encelle, Yannick Prié, Olivier Aubert.. (2010) Annotations pour l'accessibilité des vidéos dans le cas du handicap visuel in Handicap 2010, Jun 2010, Paris, France. IFRATH, pp.130-136, 2010. Show abstract L'accessibilité des contenus vidéo aux personnes en situation de handicap représente un enjeu important pour l'égalité de l'accès aux ressources numériques. Cet article expose une approche à base de métadonnées visant à améliorer l'accessibilité des vidéos aux personnes mal et non-voyantes. On ajoute dans un premier temps à une vidéo des annotations qui décrivent textuellement des éléments visuels clefs de son contenu. Dans un deuxième temps, on construit, à l'aide de modes de présentation de ces annotations et de la vidéo, des rendus enrichis de celle-ci, accessibles. Après le recueil et l'analyses des besoins des non-voyants, nous avons mené une étude préliminaire permettant d'évaluer notre approche et les mécanismes associés. Le développement de ces propositions et leur application à d'autres types de handicaps sont discutés et des perspectives, en cours d'étude au sein du projet ACAV (Annotation Collaborative pour l'Accessibilité Vidéo), sont exposées.
Additional comments
ACAV means “Annotation collaborative pour l’accessibilité vidéo”.
We had already began playing with Advene on video annotations and accessibility, and the ACAV project allowed us to get funding to get further.
Additional illustrations
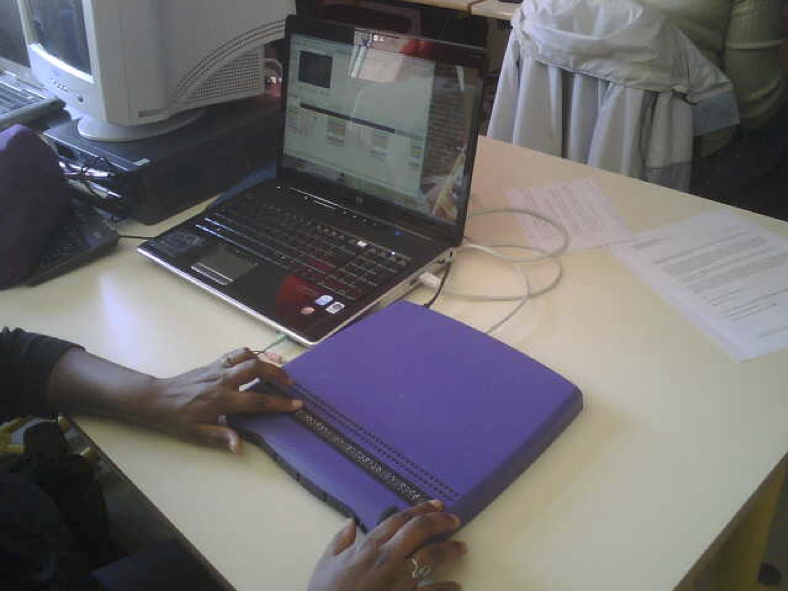
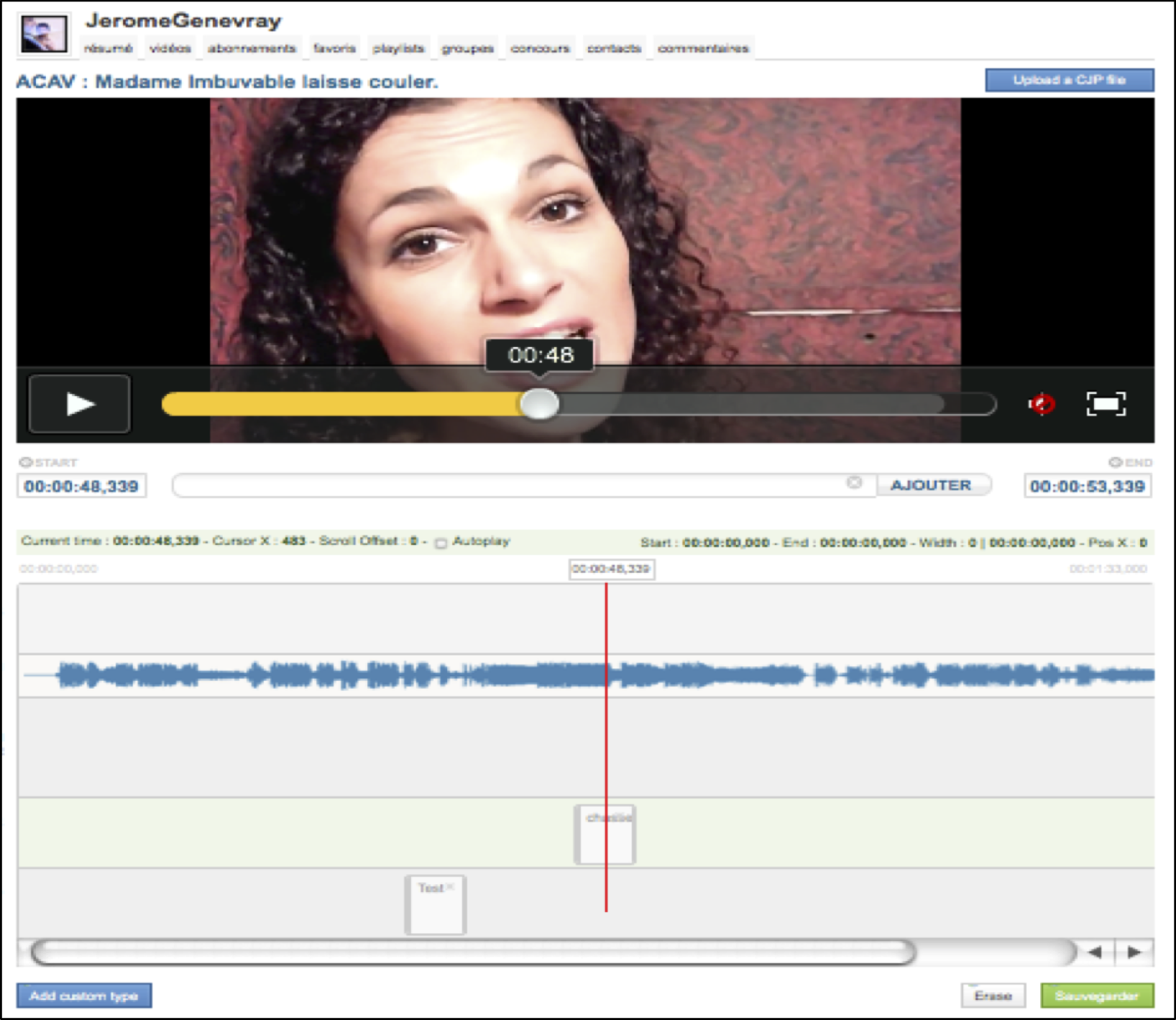
-
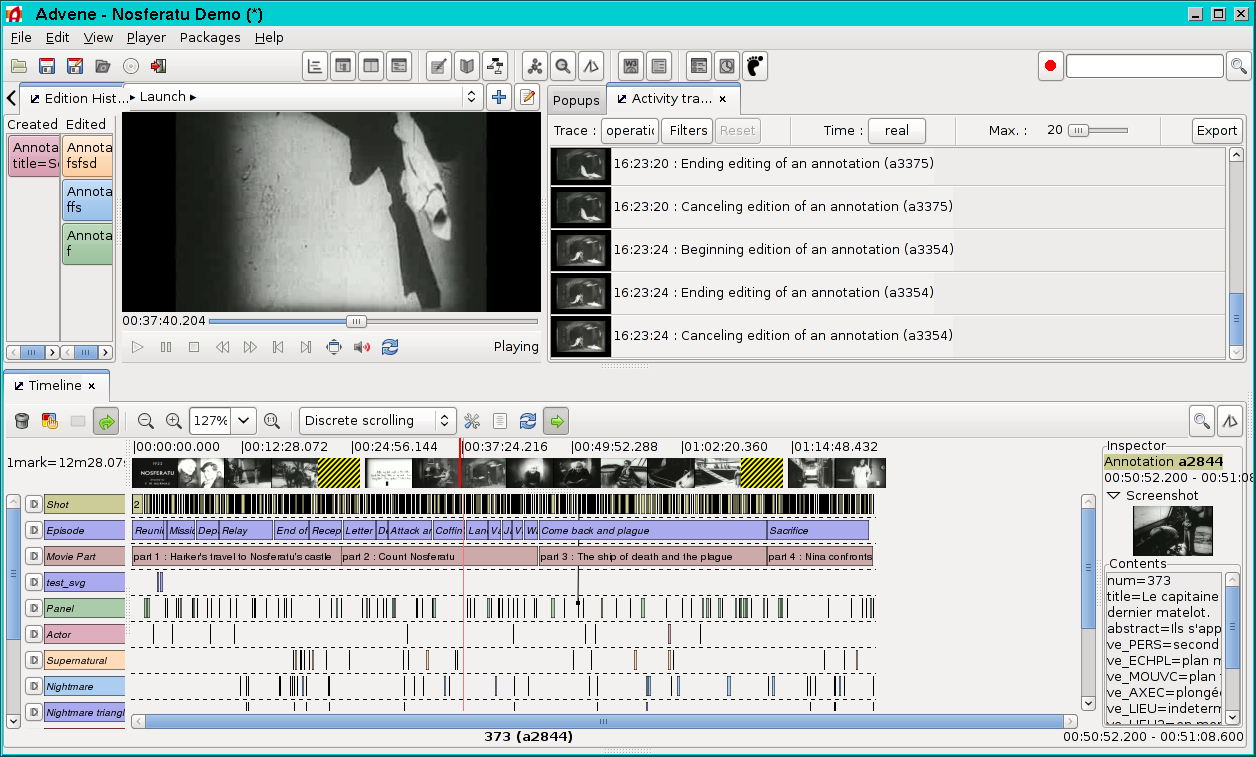
ADVENE: Annotate Digital Video, Exchange on the NEt
Document Engineering
Hypervideos
Interpretation Systems
Reflective Systems
Video Annotations
Project on video annotations, hypervideos, concept, models and tools for video active reading. The Open-Source Advene software runs on Windows, Linux and Mac OS. It features the Cinelab / Advene2 model for Hypervideo description and Exchange. A lot of information can be found on the website.
Details
Partners: Numerous
Funding: at first no funding (2003-2007), then Cinelab project on film annotations (ANR RIAM, 2007-2008, with LIRIS, IRI Centre Pompidou, Forum des Images, Antenna Audio), then Bertrand Richard PhD thesis, and other projects (notably Cinecast on Film Digital Libraries).
Beginning: 2002-10-01
End: false
Website: http://advene.org
Related publications
-
Olivier Aubert, Yannick Prié, Daniel Schmitt. (2012) Advene as a Tailorable Hypervideo Authoring Tool: a Case Study in ACM Symposium on Document Engineering, Paris, sept 2012, pp. 79-82 . doi Show abstract Audiovisual documents provide a great primary material for analysis in multiple domains, such as sociology or interaction studies. Video annotation tools offer new ways of analysing these documents, beyond the conventional transcription. However, these tools are often dedicated to specific domains, putting constraints on the data model or interfaces that may not be convenient for alternative uses. Moreover, most tools serve as exploratory and analysis instruments only, not proposing export formats suitable for publication. We describe in this paper a usage of the Advene software, a versatile video annotation tool that can be tailored for various kinds of analyses: users can define their own analysis structure and visualizations, and share their analyses either as structured annotations with visualization templates, or published on the Web as hypervideo documents. We explain how users can customize the software through the definition of their own data structures and visualizations. We illustrate this adaptability through an actual usage for interview analysis.
-
Yannick Prié. (2009) Interacting with Annotated Videos in In Workshop Interacting with temporal data at CHI 2009. Boston, MA, April 2009. 4pp. Show abstract We present Advene, a project and a prototype dedicated to video active reading, i.e. inscribing annotations on a video document and taking advantage of these annotations for navigating it. Both the video and its annotations are temporal data that need to be presented and interacted with. We present some illustrative interfaces, and discuss some of the challenges related to such a complex activity.
-
Olivier Aubert, Pierre-Antoine Champin, Yannick Prié, Bertrand Richard. (2008) Canonical processes in active reading and hypervideo production in Multimedia Systems Journal, Special Issue on Canonical Processes of Media Production. 14(6):427-433, 2008 doi Show abstract Active reading of audiovisual documents is an iterative activity, dedicated to the analysis of the audiovisual source through its enrichment with structured metadata and the definition of appropriate visualisation means for this metadata, producing new multimedia objects called hypervideos. We will describe in this article the general decomposition of active reading and how it is put into practice in the Advene framework, analysing how its activities fit into the Canonical Media Processes model.
-
Bertrand Richard, Yannick Prié, Sylvie Calabretto. (2008) Towards a unified model for audiovisual active reading in Tenth IEEE International Symposium on Multimedia, Berkeley, CA, USA, dec 2008. [AR:24%] doi Show abstract Audiovisual active reading is a commonly practised activity in different fields. This creative process consists in describing, criticizing and building an analysis during the reading of a document. More and more tools aim at providing ways to perform part of this activity, built on diferent description models. However, the whole activity is lacking a full support. In this paper, we present our work on a unified model for active reading of audiovisual documents, taking into account each part of this activity. Our approach is based on active reading data and activity modeling so as to propose a pertinent, generic and adaptive model.
-
Olivier Aubert, Pierre-Antoine Champin, Yannick Prié. (2008) Advene, une plate-forme ouverte pour la construction d'hypervidéos in Ludovia 2008, Ax-les-Thermes, aug 2008, 10 pp. Show abstract Nous présentons le projet Advene et les enjeux abordés : 1/ la question du public visé et apte à s'emparer d'un nouvel outil pour construire de nouvelles pratiques ; 2/ la souplesse nécessaire pour permettre de développer des pratiques innovantes (qui pourra entrer en conflit avec la nécessaire convivialité d'un outil s'adressant à un large public) ; 3/ les enjeux soulevés par le projet qui dépassent largement des aspects techniques ou ergonomiques et posent également des questions sur le droit d'auteur.
-
Yannick Prié, Ilias Yocaris. (2007) Informatique et analyse filmique : indécidabilité et contagion sémiotique dans Epidemic de Lars von Trier in Semio 2007, 8pp. Show abstract D’un point de vue strictement technique, notre exposé vise à esquisser une méthode de travail permettant de créer de nouveaux outils stylistiques destinés à l’analyse filmique. Pour ce faire, nous nous proposons d’analyser le film de Lars Von Trier et Niels Vørsel Epidemic (1988 ; tourné en noir et blanc). Partant d’une étude détaillée du fonctionnement sémio-stylistique de ce film, nous entendons montrer : (1) Qu’il se présente comme un « système textuel » (cf. Metz 1971 : 107-108 et passim) découlant d’une série d’interactions extrêmement complexes entre différents codes sémiotiques (discursifs, picturaux, narratifs, génériques …) ; (2) Que sa dimension « pluri-codique » (Metz 1971 : 90) doit être décrite dans le cadre d’une approche résolument interdisciplinaire, permettant de conjoindre aux acquis de la sémiotique filmique une série de concepts empruntés à la stylistique textuelle (le concept riffaterrien de « convergence »), à la narratologie (le concept genettien de « métalepse narrative »), à la philosophie du langage (le concept goodmanien d’« exemplification », le concept derridien d’« indécidabilité ») etc. ; (3) Que l’efficacité d’une telle démarche d’analyse est démultipliée par l’utilisation d’outils informatiques adéquats, qui peuvent être développés ad hoc.
-
Pierre-Antoine Champin, Yannick Prié. (2007) Models for sustaining emergence of practices for hypervideo in International Workshop On Semantically Aware Document Processing And Indexing (SADPI'07), May 2007, 10pp. Show abstract The work presented in this paper aims at covering several domains: hypervideo modelling, document annotation, and practices sharing and emergence. It is based on the Advene project, providing a model and a prototype for creating, rendering and sharing annotations of audiovisual documents. After a presentation of the notion of multi-structurality in documents and a definition of hypervideos, we present the original Advene model. We then discuss some limitations observed in our model, and introduce a new model for hypervideos. We finally discuss related work with respect to our model, and raise the problem of the emergence of semantics in videos and hypervideos.
-
Olivier Aubert, Yannick Prié. (2007) Annotations de documents audiovisuels - Temporalisation et spatialisation in Atelier Interfaces pour l'annotation et la manipulation d'objets temporels : une comparaison des outils et des paradigmes dans le domaine musical et cinématographique, nov 2007, Paris. Show abstract Le prototype open-source Advene offre une plateforme pour l’intégration, la visualisation et l’échange de métadonnées sur des documents audiovisuels. Il permet aux utilisateurs de définir eux-mêmes, en fonction des tâches à effectuer, les structures des métadonnées et la manière de les visualiser. Il permet ainsi de mettre en ½uvre des pratiques de lecture active de documents audiovisuels. Nous présentons ici quelques éléments de réflexion sur la pratique d’annotation de documents temporalisés.
-
Bertrand Richard, Yannick Prié, Sylvie Calabretto. (2007) Lecture active de documents audiovisuels : organisation de connaissances personnelles par la structuration d’annotations in Ingénierie des Connaissances 2007, Grenoble, July 2007, 12 pp. Show abstract Au cours de la pratique de la lecture active, un lecteur manipule une quantité importante de connaissances, liées à sa pratique et au document étudié. Ces connaissances au coeur de l’activité sont amenées à évoluer afin de correspondre au mieux à la pratique du lecteur. Nous présentons dans cet article nos réflexions relatives à la construction et la manipulation de connaissances personnelles au cours de cette activité et à l’évolution de ces connaissances au fil de la pratique. Après étude des modèles existants, nous proposons un modèle de structuration de connaissances adapté aux contraintes de la lecture active et permettant de diffuser les différentes pratiques de la lecture active.
-
Olivier Aubert, Yannick Prié. (2007) Advene: an open-source framework for integrating and visualising audiovisual metadata in Open Source Competition: Technical presentation and overview paper, Proc. of ACM Multimedia Conference, Augsburg, sept. 2007, pp. 1005-1008. doi Show abstract The open-source Advene prototype offers a framework for integrating and visualising audiovisual metadata. It allows users to define by themselves, according to their specific tasks, the structure of the metadata as well as the different ways in which it should be visualised. By storing metadata and visualisation specifications independently from the audiovisual document, it allows to share analyses and comments on any audiovisual document. Its open nature and simple principles make it an ideal testbed for experimentation with new audiovisual metadata interaction modalities.
-
Olivier Aubert, Yannick Prié. (2006) Des vidéos aux hypervidéos : vers d'autres interactions avec les médias audiovisuels in Technique et science informatique, Vol 25, num 4, 2006, pp. 409-436, 2006. doi Show abstract La numérisation des documents permet d'en envisager des exploitations novatrices, comme la démontré le succès du web. La capacité des systèmes informatiques permet maintenant d'exploiter les documents audiovisuels, mais tous les concepts et outils ne sont pas encore présents. Afin de fournir un support à la réflexion sur les utilisations innovantes des documents audiovisuels numériques, nous présentons et discutons ici la notion d'hypervidéo, qui permet d'une part, d'analyser des instances existantes d'hypervidéos, et d'autre part, de donner un guide de construction pour des systèmes mettant en oeuvre les hypervidéos. Nous décrivons ensuite le projet Advene, qui vise à fournir une plate-forme permettant 1) la création d'hypervidéos (visualisations dynamiques et statiques de données associées à un médium audiovisuel) ; 2) l'échange des données et des vues associées, afin de permettre un travail collaboratif sur ce type de médium.
-
Olivier Aubert, Pierre-Antoine Champin and Yannick Prié. (2006) Integration of Semantic Web Technology in an Annotation-based Hypervideo System in SWAMM 2006, 1st International Workshop on Semantic Web Annotations for Multimedia, Held as part of the 15th World Wide Web Conference, May 2006, 12 pp. Show abstract This article discusses the integration of semantic web technologies (ontology and inference) into audiovisual annotation based models and systems. The Advene project, aimed at all purpose hypervideo generation from annotated audiovisual documents, is used as a testbed. Advene principles and the Advene prototype are first presented, before a discussion on how ontology and reasoning have been easily integrated into the Advene framework. Some motivating examples are proposed, and our proposals and related works are discussed.
-
Olivier Aubert, Yannick Prié. (2005) Des hypervidéos pour créer et échanger des analyses de documents audiovisuels in H2PTM 2005, Créer, jouer, échanger : expériences de réseaux, nov. 2005, Paris, 10 pp. Show abstract Les possibilités offertes par l'hypertexte ne sont pas encore très exploitées dès lors que l'on travaille avec des documents audiovisuels. Le besoin de métadonnées y est plus immédia- tement perceptible, la temporalité des documents pose des problèmes nouveaux en termes de manipulation et d'interaction, et la question des droits étant loin d'être réglée. Afin de pouvoir analyser les expérimentations novatrices actuelles dans ce domaine et éclairer la construction de nouveaux systèmes, nous présentons la notion d'hypervidéo comme cadre général mettant en évidence différentes dimensions des hypermédias à base de documents audiovisuels. Le projet open-source Advene nous permet de mener des expérimentations de mise en application des hypervidéos et fournit un support à l'innovation par le bas propice à l'émergence de nouveaux modes d'interaction audiovisuelle.
-
Olivier Aubert and Yannick Prié. (2005) Advene: Active Reading through Hypervideos in ACM Conference on Hypertext and Hypermedia 05, 2005, Salzburg, Austria, pp. 235-244. [AR:36%] doi Show abstract Active reading and hypermedia usage are an integral part of scholar daily practices, but the full exploitation of their potentialities still lies far ahead. In the search for new methods and tools, we focus in this article on the use of audiovisual material in a scholar context. One of the results of active reading applied to audiovisual material can be hypervideos, that we define as views on audiovisual documents associated with an annotation structure. The notion of hypervideo is useful to analyse existing video-based hypermedia systems as well as building new systems. The Advene project proposes an implementation of hypervideos through a framework that allows experimentations of new visualisation and interaction modalities for enriched videos.
-
Olivier Aubert, Yannick Prié. (2004) Documents audiovisuels instrumentés. Temporalités et détemporalisations dans les hypervidéos in Document numérique, numéro spécial : Temps et document, vol. 8, num. 4, pp.143-168, 2004. doi Show abstract Nous nous intéressons tout d’abord dans cet article aux documents audiovisuels et aux diverses temporalités qui leur sont liées. Après un état des lieux des possibilités actuelles des systèmes d’information audiovisuelle, nous définissons plus précisément ce que sont les hyper- vidéos, ou documents audiovisuels numériques instrumentés. Nous décrivons et illustrons alors un certain nombre des caractéristiques des objets hypervidéos en lien avec les temporalités dé- finies, qui en font des objets complexes. Nous présentons alors un début de cadre d’analyse des synchronisations entre temporalités des hypervidéos générées et vécues.
-
Olivier Aubert, Yannick Prié. (2004) From video information retrieval to hypervideo management in International Workshop on Multidisciplinary Image, Video, and Audio Retrieval and Mining. Sherbrooke-Canada, October 25-26 2004 Show abstract The digital revolution that has somehow taken place with the World-Wide Web took advantage of the availability and interoperability of tools for visualisation and manipulation of text-based data, as well as the satisfying pertinence of search engines results that makes them usable by non-expert users. If we are to undergo such a revolution in the audiovisual domain, a number of issues mainly related to the temporal nature of audiovisual documents have to be resolved. In this article, we expose our view of the current state of Audiovisual Information Systems, and suggest that they should be considered as video information management systems rather than video retrieval systems, in order to foster new uses of video information. We define the notion of hypervideo that can be used as an analysis framework for this issue. We then describe our implementation of hypervideos in the Advene framework, which is aimed at DVD material annotation and analysis. We eventually discuss how the notion of hypervideo puts video information retrieval in a somewhat different light.
-
Olivier Aubert, Pierre-Antoine Champin, Yannick Prié. (2003) Instrumentation de documents audiovisuels : temporalisations et détemporalisation dans le projet Advene in Workshop "Temps et documents numériques", Nov 2003, Grenoble, France. 2003 Show abstract Nous présentons dans cet article les différents éléments du modèle Advene pour représenter des annotations audiovisuelles, et présenter celles-ci à l’utilisateur sous la forme l’hypervidéos, documents hypermédias générés à partir du document audiovisuel original annoté et des annotations. Les hypervidéos sont des documents multimédias complexes, du fait de la part importante prise par l’élément vidéo, qui possède des temporalités particulières. Afin d’être à même de construire des hypervidéos conduisant à des utilisations novatrices du matériel audiovisuel, nous proposons un modèle d’analyse de celles-ci suivant différentes temporalités.
Related software
Additional comments
Please use ACM Hypertext 2005 reference as main citation.
Additional illustrations
-
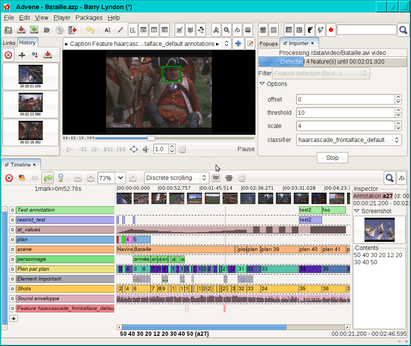
Cinecast: Film enrichments and video metadata exchange
Document Engineering
Interpretation Systems
Video Annotations
Film enrichment in public film libraries and on the web. Exchange of film annotations on social networks. We worked on hypervideos models, and video annotations sharing.
Details
Partners: Researchers (LIRIS, IRI / Centre Pompidou, LIST / CEA, Telecom Paris Tech); major film libraries (Forum des Images, Cinémathèque française, BNF, BPI, INA); and industrial partners (NETIA, Globe Cast, Univers Ciné, lesite.tv, Jamespot, Exalead, Allociné, VodKaster).
Funding: French Industry Ministry funding, FUI9 call
Beginning: 2010-10-01
End: 2012-12-31
Related publications
-
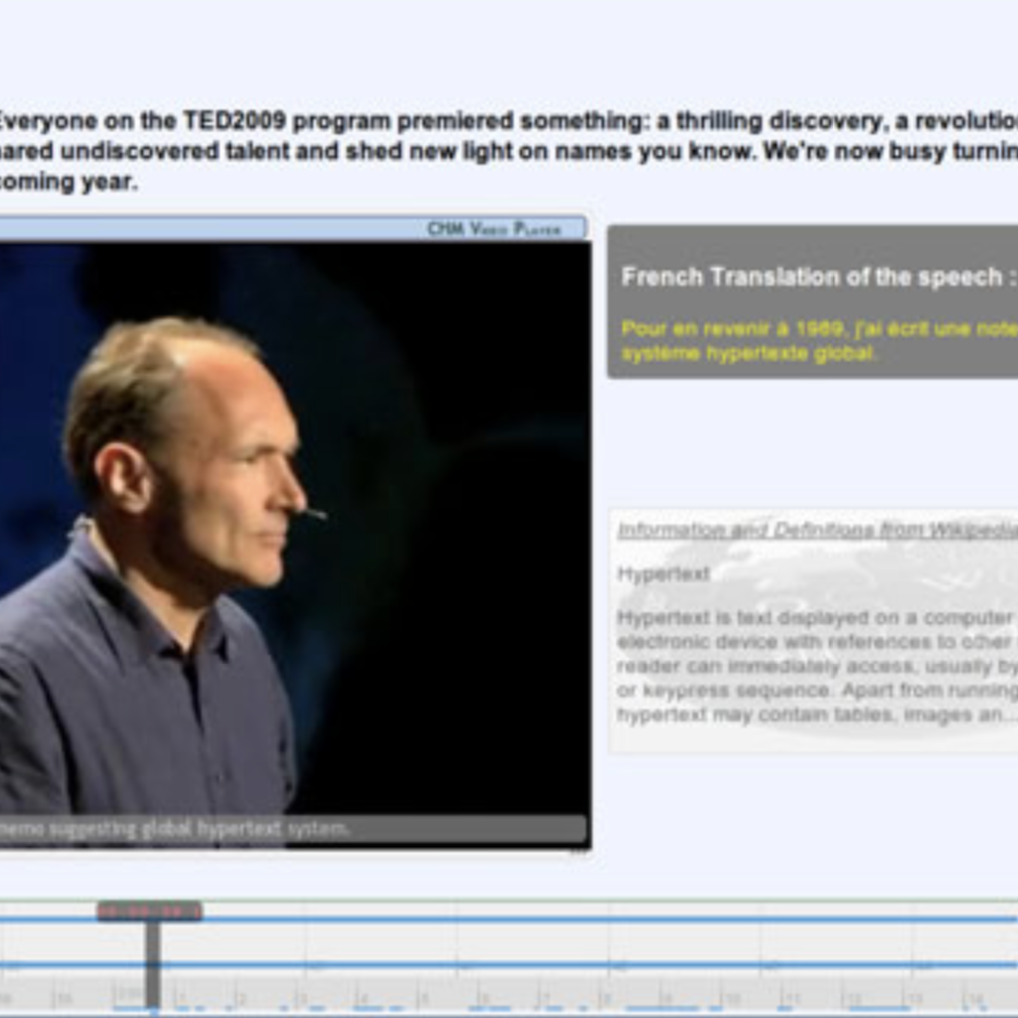
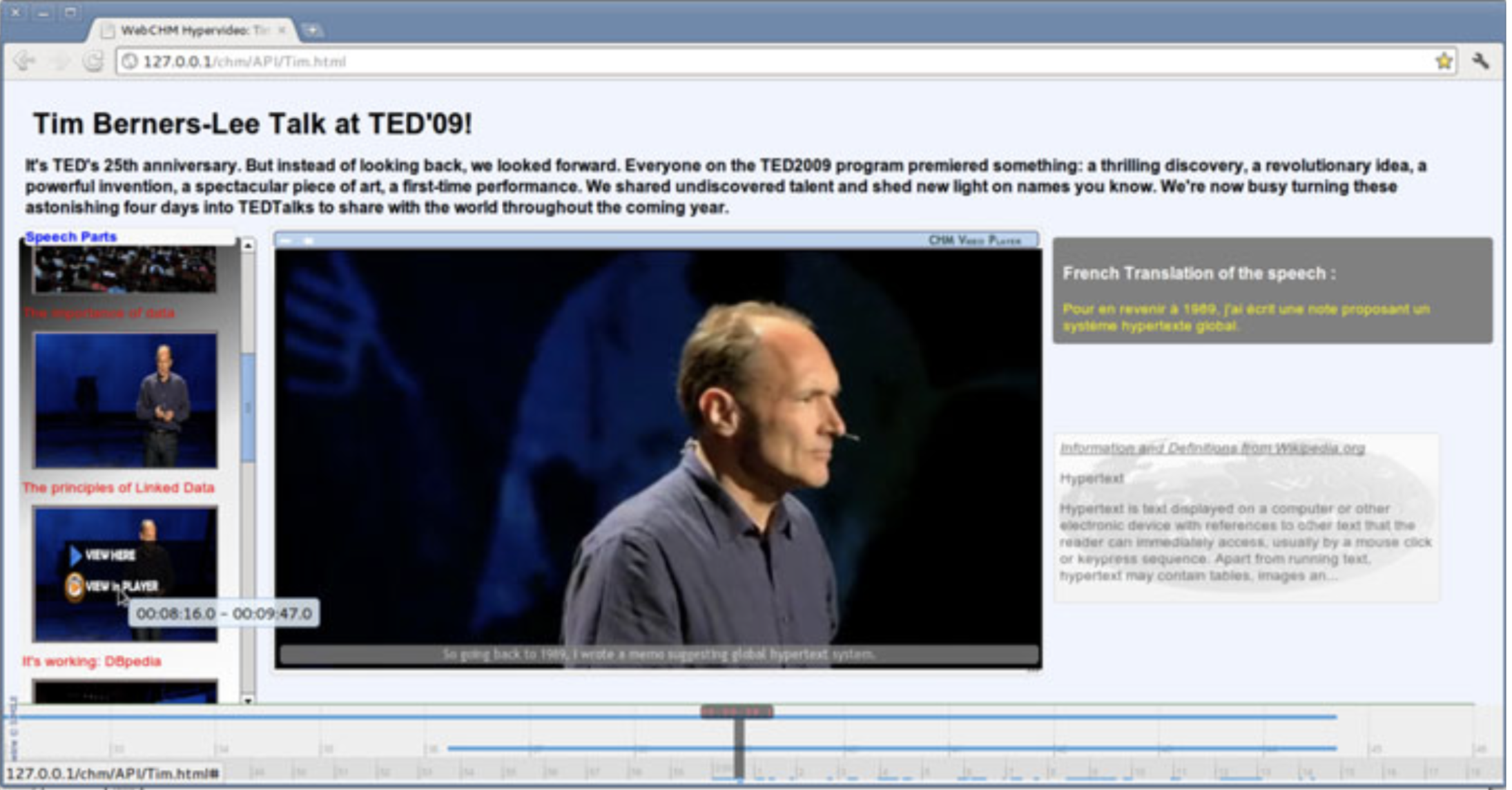
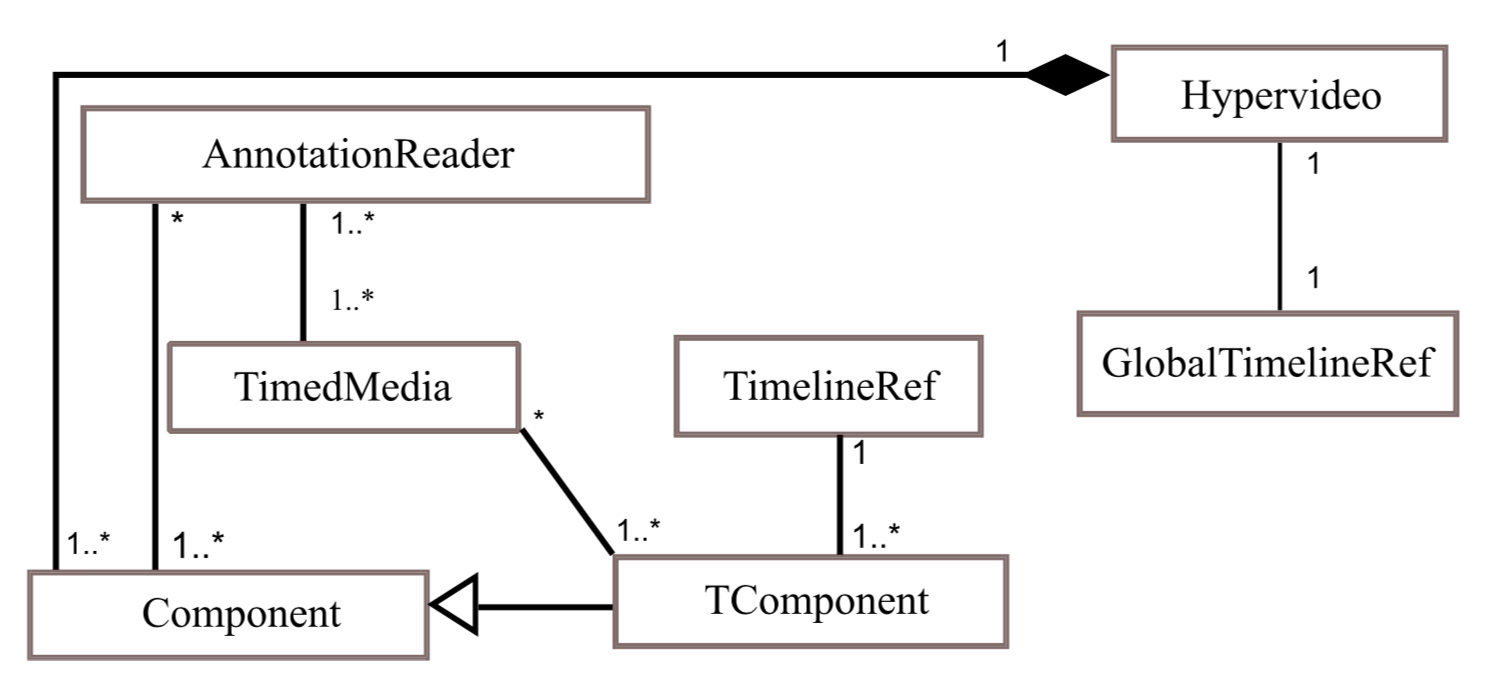
Madjid Sadallah, Olivier Aubert, Yannick Prié. (2014) CHM: an Annotation- and Component-based Hypervideo Model for the Web in Multimedia Tools and Applications, 70(2), 869-903, may 2014 doi Show abstract Hypervideos are hypermedia documents that focus on video content. While they have long been deployed using specialized software or even hardware, the Web now offers a ground for them to fit into standardized languages and implementations. However, hypervideo design also currently uses very specific models limited to a single class of documents, or very generic hypermedia models that may not appropriately express their specific features. In this article we describe such features, and we introduce CHM, an annotation-driven and component-based model to conceptualize hypervideos through a high level operational specification. An extensible set of high level components is defined to emphasize the presentation and interaction features modeling, while lower level components offer more flexibility and customization opportunities. Being annotation-based, the model promotes a clear separation between video content/metadata and their various potential presentations. We also describe WebCHM, an implementation of CHM with standard Web technologies that provides a general framework to experiment with hypervideos on the Web. Two examples are provided as well as a preliminary usage study of the model and its implementation to validate our claims and proposals.
-
Yannick Prié, Vincent Puig. (2013) Nouveaux modes de perception active de films annotés in Cinéma, interactivité et société, direction, ouvrage, Université de Poitiers & CNRS, pp. 373-387. 2013 Show abstract Notre approche est à la fois théorique et technologique. Théoriquement, il s’agit de (re)penser nos rapports d’appropriation au sens large des ½uvres cinématographiques en s’appuyant sur les possibilités de perception active offertes par le numérique. Technologiquement, il s’agit alors de se donner les moyens de décrire et d’implémenter différents outils de perception active de corpus de films. La notion d’annotation audiovisuelle comme matérialisation première de toute rencontre avec celui-ci est à cet égard centrale et sert de base à la construction d’un cadre de pensée adéquat de la perception active. Nous décrivons quelques exemples d’outils de lecture active de films pour la critique et l'enseignement, ainsi que des dispositifs artistiques de restitution. Différentes questions de recherche en cours d’exploration sont enfin abordées et permettent d’illustrer la richesse des travaux en cours.
-
Madjid Sadallah, Olivier Aubert, Yannick Prié. (2011) Hypervideo and Annotations on the Web in Workshop on Multimedia on the Web 2011. Graz, Austria. Sept 2011. doi Show abstract Effective video-based Web information system deployment is still challenging, while the recent widespread of multimedia further raises the demand for new online audiovisual document edition and presentation alternatives. Hyper video, a specialization of hypermedia focusing on video, can be used on the Web to provide a basis for video-centric documents and to allow more elaborated practices of online video. In this paper, we propose an annotation-driven model to conceptualize hyper videos, promoting a clear separation between video content/metadata and their various potential presentations. Using the proposed model, features of hyper video are grafted to wider video-based Web documents in a Web standards-compliant manner. The annotation-driven hyper video model and its implementation offer a general framework to experiment with new interaction modalities for video-based knowledge communication on the Web.
-
Madjid Sadallah, Olivier Aubert, Yannick Prié. (2011) Component-based Hypervideo Model: high-level operational specification of hypervideos in ACM DocEng. Mountain View, California. pp. 53-56. Sept 2011. doi Show abstract Hypervideo offers enhanced video-centric experiences. Usually defined from a hypermedia perspective, the lack of a dedicated specification hampers hypervideo domain and concepts from being broadly investigated. This article proposes a specialized hypervideo model that addresses hypervideo specificities. Following the principles of component-based modeling and annotation-driven content abstracting, the Component-based Hypervideo Model (CHM) that we propose is a high level representation of hypervideos that intends to provide a general and dedicated hypervideo data model. Considered as a video-centric interactive document, the CHM hypervideo presentation and interaction features are expressed through a high level operational specification. Our annotation-driven approach promotes a clear separation of data from video content and document visualizations. The model serves as a basis for a Web-oriented implementation that provides a declarative syntax and accompanying tools for hypervideo document design in a Web standards-compliant manner.
-
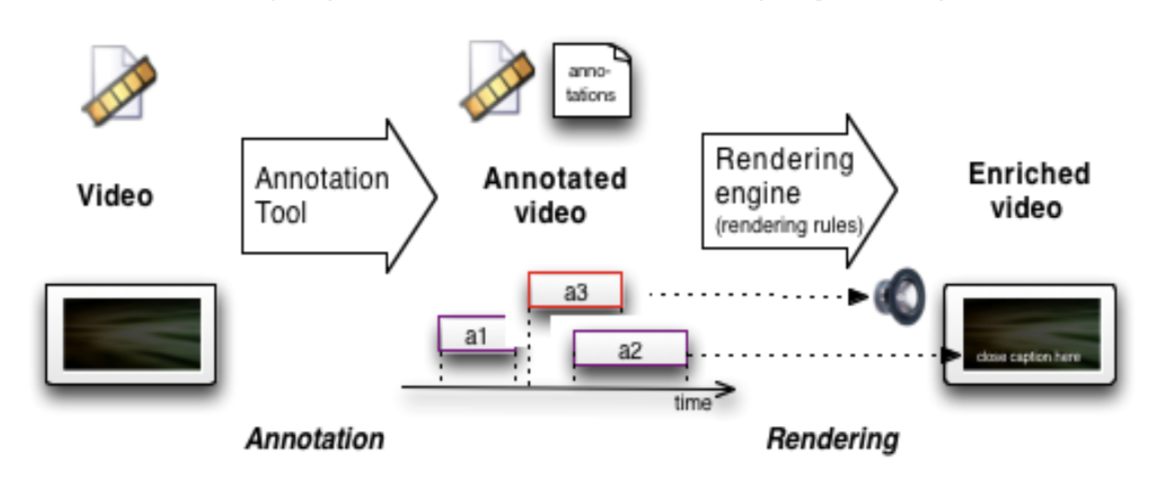
Benoît Encelle, Pierre-Antoine Champin, Yannick Prié, Olivier Aubert. (2011) Models for Video Enrichment in Proceedings of the 11th ACM symposium on Document engineering. Mountain View, California. pp. 85-88. Sept 2011. doi Show abstract Videos are commonly being augmented with additional content such as captions, images, audio, hyperlinks, etc., which are rendered while the video is being played. We call the result of this rendering "enriched videos". This article details an annotation-based approach for producing enriched videos: enrichment is mainly composed of textual annotations associated to temporal parts of the video that are rendered while playing it. The key notion of enriched video and associated concepts is first introduced and we second expose the models we have developed for annotating videos and for presenting annotations during the playing of the videos. Finally, an overview of a general workflow for producing/viewing enriched videos is presented. This workflow particularly illustrates the usage of the proposed models in order to improve the accessibility of videos for sensory disabled people.
Related software
Additional comments
This ambitious project was featuring a really great line up.
Additional illustrations
-
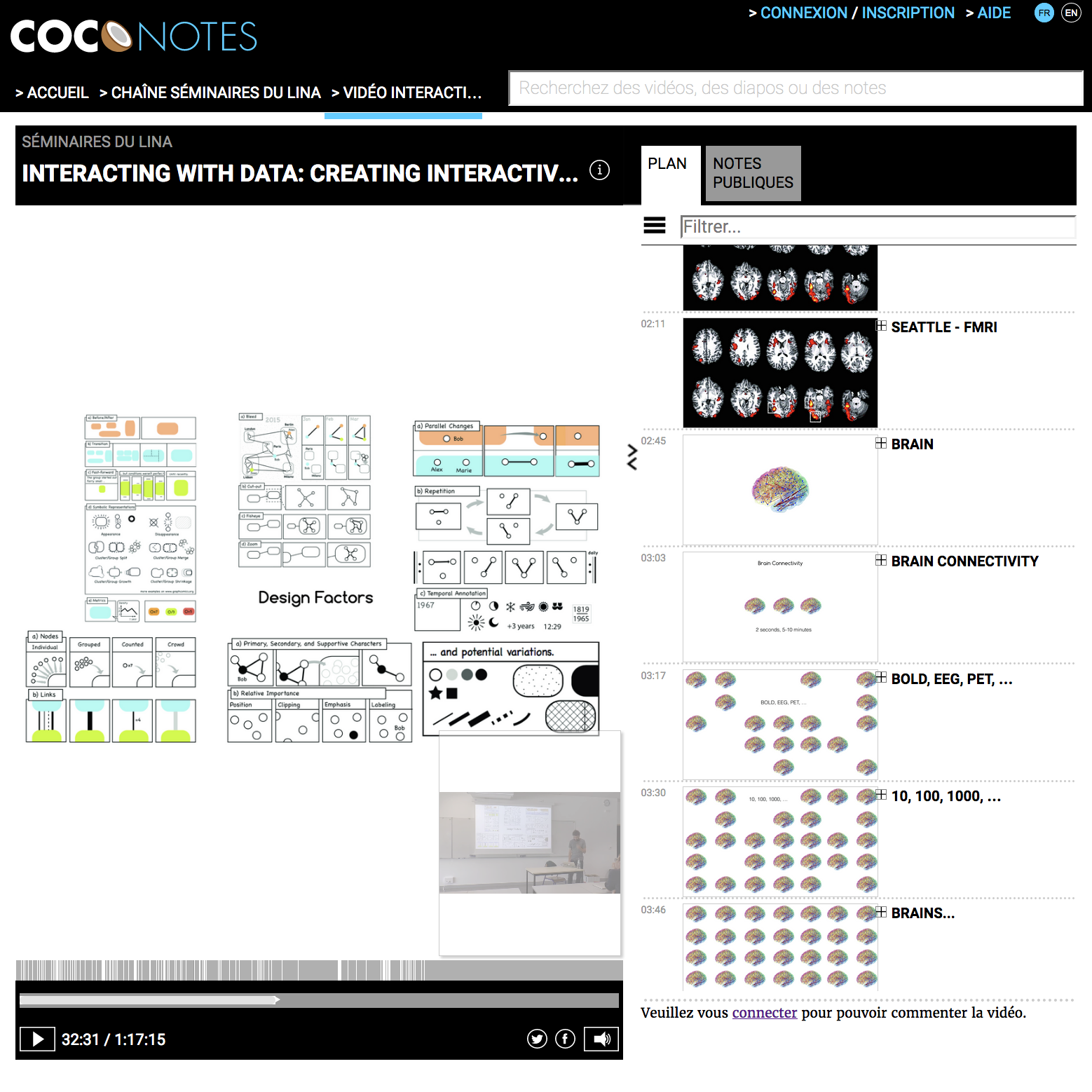
COCo: Comin Open Courseware
Technology-Enhanced Learning
Hypervideos
Video Annotations
Research and development aimed at leveraging annotations in video-centered pedagogical resources, creating open courseware multimodal content for knowledge diffusion, and exploring new techniques for e-learning. More than 30 courses and seminar videos have been produced.
Details
Partners: LS2N
Funding: Labex Cominlabs
Cofunding: Région Pays de la Loire
Beginning: 2013-09-01
End: 2016-12-31
Website: http://www.comin-ocw.org/
Related publications
-
Camila Canellas, Olivier Aubert, Yannick Prié. (2015) Prise de note collaborative en vue d’une tâche : une étude exploratoire avec COCoNotes Live in 17ème Conférence sur les Environnements Informatiques pour l'Apprentissage Humain (EIAH 2015), Jun 2015, Agadir, Maroc. pp.204-209, 2015 Show abstract Les enregistrements de présentations orales telles que celles effectuées lors de conférences peuvent souvent constituer une base pour 1) une nouvelle activité basée sur leur contenu, 2) une autre forme pour le même contenu, ou 3) une combinaison avec d'autres documents. Cependant, les enregistrements vidéo peuvent se révéler difficiles à naviguer et explorer. Nous présentons ici les résultats préliminaires d’une situation où un outil de microblogging est utilisé durant l'enregistrement pour produire des annotations catégorisées et synchronisées avec l'enregistrement. Les annotations sont ensuite utilisées pour naviguer dans l'enregistrement et produire de nouveaux documents, dans le contexte d'une tâche spécifique.
-
Olivier Aubert, Yannick Prié, Camila Canellas. (2014) Leveraging video annotations in video-based e-learning in 6th International Conference on Computer Supported Education, Barcelona, Spain, April 2014 Show abstract The e-learning community has been producing and using video content for a long time, and in the last years, the advent of MOOCs greatly relied on video recordings of teacher courses. Video annotations are information pieces that can be anchored in the temporality of the video so as to sustain various processes ranging from active reading to rich media editing. In this position paper we study how video annotations can be used in an e-learning context - especially MOOCs - from the triple point of view of pedagogical processes, current technical platforms functionalities, and current challenges. Our analysis is that there is still plenty of room for leveraging video annotations in MOOCs beyond simple active reading, namely live annotation, performance annotation and annotation for assignment; and that new developments are needed to accompany this evolution.
Related software
Additional comments
The project was focused on open education and open course ware (OCW), all material is available on the project website.
-
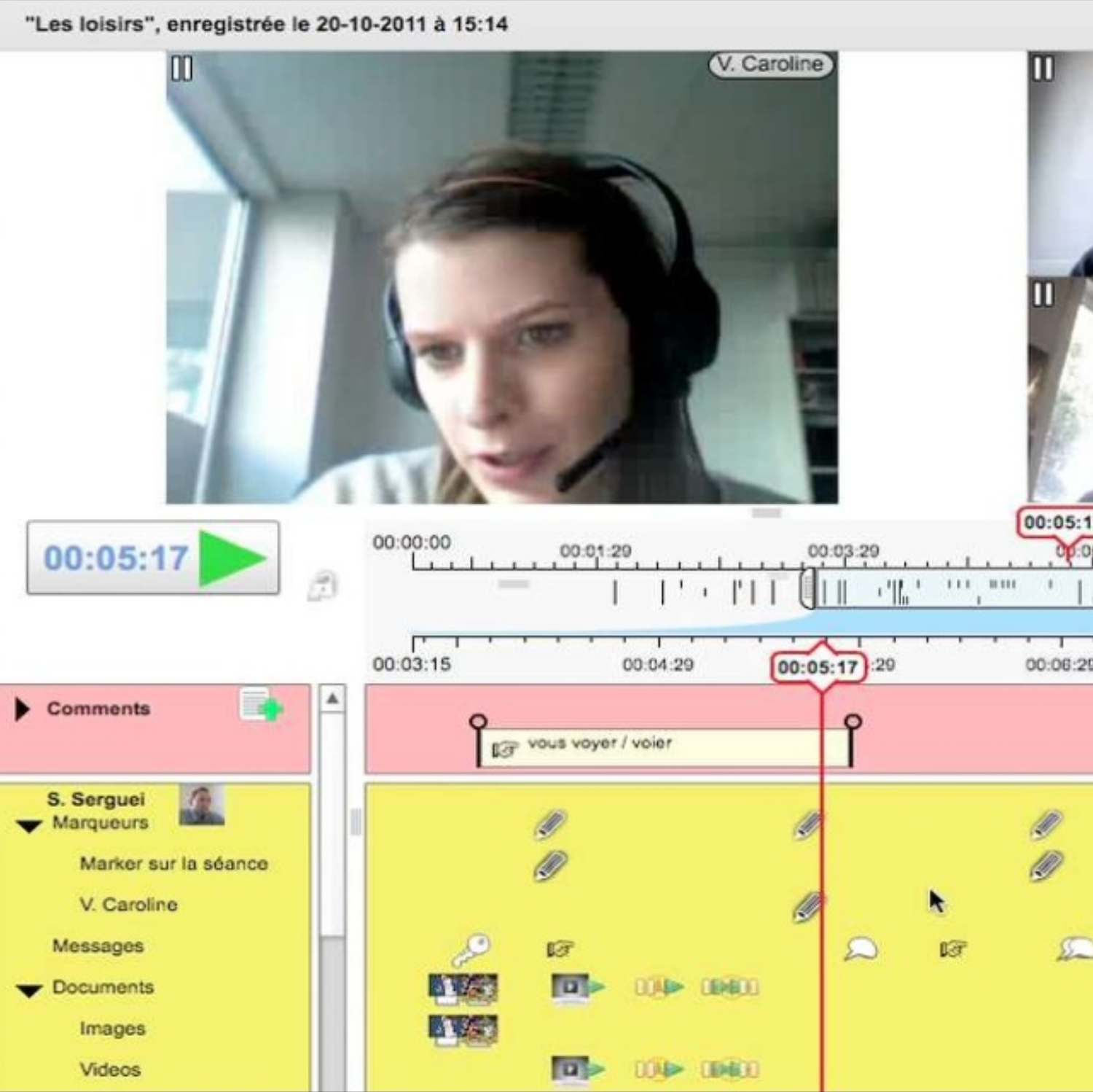
ITHACA: Interative Trace for Human Awareness in Collaborative Annotation
Reflective Systems
Technology-Enhanced Learning
Trace-based Systems
Video Annotations
In this project carried with education scientists, we explored the use of traces in synchronous videoconference-based communication, mainly in the context of language teaching. We built two versions of the Visu tool, that was used in multiple settings..
Details
Partners: LIRIS, Lyon 2 University, ICAR Laoratory, TECFA Geneva
Funding: French National Research Agency (ANR)
Beginning: 2008-10-01
End: 2011-12-31
Website: https://projet.liris.cnrs.fr/ithaca/
Related publications
-
Elise Lavoué, Gaëlle Molinari, Yannick Prié, Safè Khezami. (2015) Reflection-in-Action Markers for Reflection-on-Action in Computer-Supported Collaborative Learning Settings in Computers & Education, Volume 88, October 2015, Pages 129–142. doi Show abstract We describe an exploratory study on the use of markers set during a synchronous collaborative interaction (reflection-in-action) for later construction of reflection reports upon the collaboration that occurred (reflection-on-action). During two sessions, pairs of students used the Visu videoconferencing tool for synchronous interaction and marker setting (positive, negative or free) and then individual report building on the interaction (using markers or not). A quantitative descriptive analysis was conducted on the markers put in action, on their use to reflect on action and on the reflection categories of the sentences in these reports. Results show that the students (1) used the markers equally as a note-taking and reflection means during the interaction, (2) used mainly positive markers both to reflect in and on action; (3) paid more attention in identifying what worked in their interaction (conservative direction) rather than in planning on how to improve their group work (progressive direction); (4) used mainly their own markers to reflect on action, with an increase in the use of their partners' markers in the second reflection reports; (5) reflected mainly on their partner in the first reflection reports and more on themselves in the second reports to justify themselves and to express their satisfaction.
-
Elise Lavoué, Gaëlle Molinari, Safè Khezamy, Yannick Prié. (2013) How do Students Use Socio-Emotional Markers for Self-Reflection on their Group Work in CSCL Settings? A Study with Visu: a Synchronous and Delayed Reflection Tool in 10th International Conference on Computer Supported Collaborative Learning, Madison, USA, 2013 [AR:39%] Show abstract This paper describes an exploratory study on the use of reflective markers set during synchronous collaborative learning sessions (reflection in action) for later construction of self-reflection reports upon the collaboration that occurred (reflection on action). During 2 sessions, students used the Visu tool for interaction and marker setting (positive, negative, free) and then report building on the interaction (using markers or not). A quantitative descriptive analysis has been conducted on the markers used and on the reflective categories of the sentences in the reports. Results show that students (1) paid more attention in repairing their relationship than reflecting on learning and task goals; (2) used mainly positive markers to both reflect in and on action; (3) used more their partner's markers in the second reports; (4) reflected more on themselves in the second reports to justify successes and failures, and to express satisfaction.
-
Elise Lavoué, Safè Khezami, Gaëlle Molinari, Yannick Prié. (2013) The Visu Reflection Tool for Socio-Emotional Awareness in CSCL situations in Workshop on Tools and Technologies for Emotion Awareness in Computer-Mediated Collaboration and Learning. Alpine Rendez-Vous (ARV) 2013, Villars-de-Lans, Jan 2013. Show abstract An exploratory study has been conducted in which 12 students in Bachelor of Science in Psychology were asked to use the Visu reflection tool during Computer-Supported Collaborative Learning (CSCL) situations. Visu is a web videoconferencing platform that allows participants to put reflective markers during their collaborative learning activity, and to review the traces of their synchronous collaboration later. In this study, co-learners used two types of markers: (1) free markers and (2) socio-emotional markers to express either negative or positive feelings about the way they collaborate together. Our contribution is related to the first focus of the workshop: emotion awareness in CSCL. In line with this focus, our main questions are as follows: (1) How can the Visu tool help learners express and share their feelings about collaboration? How does this affect the way they interact and learn together? (2) How do they use the Visu markers after the collaboration to self-reflect on their group processes? In this paper, we first describe the Visu platform. We then present a study we have carried out to answer the questions presented above. We finally conclude with the contributions of our research to the workshop topic.
-
Nicolas Guichon, Mireille Bétrancourt, Yannick Prié. (2012) Managing written and oral negative feedback in a synchronous online teaching situation in Computer-Assisted Language Learning, 25(2):181-197, 2012. doi Show abstract This case study focuses on the feedback that is provided by tutors to learners in the course of synchronous online teaching. More specifically, we study how trainee tutors used the affordances of Visu, an experimental web videoconferencing system, to provide negative feedback. Visu features classical functionalities such as video and chat, and it also offers a unique marking tool that allows tutors to take time-coded notes during the online interactions for later pedagogical remediation. Our study shows that tutors mainly use verbal and chat feedback, with significant inter-individual variability, and that tutors who provide verbal feedback are more likely to use markers. Marking takes time because of the dual task that it entails for the tutor. Idiosyncratic strategies in the use of markers are evidenced. These results clearly show the value of markers for negative feedback, signal the need for their explicitness, and also call for an evolution of the Visu interface so that tutors can better negotiate the task of online tutoring and the pedagogical stance they have to take on in their interactions with the learners.
-
Mireille Bétrancourt, Nicolas Guichon, Yannick Prié. (2011) Assessing the use of a Trace-Based Synchronous Tool for distant language tutoring in 9th International Conference on Computer Supported Collaborative Learning. Hong Kong. pp 486-493. Jul 2011. [AR:36%] Show abstract This article presents a pilot study carried out to investigate the potential of a functionality marker setting, included in a synchronous collaborative videoconferencing platform (VISU). Markers, supported by a trace-based system, are designed to facilitate tutors' activity. They provide tutors with (1) the possibility of annotating their distant learners' learning activity, and (2) information pertaining to their own behavior during pedagogical interaction, which can potentially enhance their professional performance as online language tutors. This study concentrates on the marker-based traces of eight language tutors collected in the course of pedagogical interactions with their distant learners during a seven-week transnational collaborative project. It presents both quantitative and qualitative analyses of the use of markers during synchronous language teaching sessions and assesses the utility and usability of such a functionality for language tutoring in order to inform future design and training.
Related software
Select another theme:
Accessibility
Affordances
Data Visualization
Digital Instruments
Document Engineering
Experience analysis and modelling
Hypervideos
Immersive Analytics
Interpretation Systems
Knowledge Engineering
Learning Analytics
Patient Experience
Progressive analytics
Reflective Systems
Technology-Enhanced Learning
Trace-based Activity Analysis
Trace-based Systems
VR and Psychotherapy
Video Annotations
Virtual Reality
